Legyen H egy tetszőleges halmaz. Válasszuk ki és rögzítsük a H halmaz n∈ℕ+ darab különböző elemét (feltéve, hogy H elemszáma legalább 'n'). Speciálisan megengedjük az n=1 esetet is.
Ekkor az (a1, a2, ..., an)
véges elemsorozatot ("rendezett elem n-est") az ai elemek egy ismétlés nélküli permutációjának nevezzük.
Legyen
Hn={ai∈H | 1≤i≤n}
a kiválasztott elemekből álló ('n' elemű) halmaz.
Ekkor a Hn halmaz elemeinek egy ismétlés nélküli permutációján a Hn halmaznak egy "önmagára vett bijektív leképezését értjük"
(Wikipédia). Ebben az értelemben a Hn halmaz elemeinek összes permutációját a Hn halmaz önmagára vett összes lehetséges bijektív leképezése adja meg.
Például, ha n=5 és Hn={1,2,3,4,5}, akkor egy lehetséges 'p' bijektív leképezést
Dom(p)
1
2
3
4
5
Rng(p)
5
2
1
3
4
módon adhatunk meg, ahol a leképezés értelmezési tartományának (Dom(p)) elemeit a táblázat felső sorában, értékkészletét (Rng(p)) pedig a táblázat alsó sorában soroljuk fel (az elemek egymáshoz rendelését pedig a táblázat megfelelő oszlopai mutatják).
Megjegyzés: a Hn (n elemű) halmaz elemeinek egy permutációját úgy is megkaphatjuk, hogy a Hn halmaz összes elemét egy adott sorrendben, egymás után kiválasztjuk (és minden elemet csak egyszer, azaz az elemet kiválasztása után "nem tesszük vissza"). Az összes lehetséges (különböző) kiválasztások száma ebben az esetben megegyezik az n elem n-ed osztályú (vagy rendű) ismétlés nélküli variációinak a számával (ld. később).
Az (a1, a2, ..., an) és (b1, b2, ..., bn) permutációk megegyeznek, ha minden elemre ai=bi (1≤i≤n) teljesül.
Egy ismétlés nélküli permutációban minden elem különböző, tehát két tetszőleges elemet felcserélve egy másik, az előzőtől különböző permutációt kapunk.
Rögzített n∈ℕ+ elemszám esetén az összes különböző ismétlés nélküli permutáció száma
P
n
= n!
módon számítható ki,
ahol az n! műveletet (n faktoriálisát) az első n természetes szám szorzataként definiáljuk:
0!⇋1 (megállapodás szerint),
1!⇋1,
2!⇋1*2,
3!⇋1*2*3,
...,
n!⇋1*2*3*4*...*n,
vagyis n! definíció szerint megegyezik az
s0=0,
s1=1,
sn=n*sn−1 (n>1)
sorozat n-ik elemével (azaz n!⇋sn).
A fentieknek megfelelően egy
véges, n elemű Hn halmaz elemeinek összes ismétlés nélküli permutációját
{
(i1,i2,...,in) |
ij∈Hn,
1≤j≤n;
ij≠ik,
1≤j<k≤n
}
módon kaphatjuk meg.
Például az (1,2,3) számok ismétlés nélküli permutációi a következőképpen állíthatók elő:
/* ismétlés nélküli permutációk, P3 (1,2,3) */
var i,j,k;
var sorszam=0;
for(var i=1;i<=3;i++) {
for(var j=1;j<=3;j++) {
if(j==i) continue;
for(var k=1;k<=3;k++) {
if(k==i || k==j) continue;
writeln("("+i+","+j+","+k+")");
sorszam++;
}
}
}
writeln();
writeln("a permutációk száma: "+sorszam);
writeln("-----");
Jegyezzük meg, hogy
– a permutációkat a Hn={1,2,3} halmaz elemeinek egymás utáni kiválasztásával kapjuk meg;
– a programban szereplő 'for' ciklusok ciklusváltozói (i,j,k) a
Hn
halmaz elemeit veszik fel;
– minden egyes 'for' ciklus egy elem "kiválasztását" valósítja meg a Hn halmazból.
A program futásának eredménye:
Ismétléses permutációk
Legyen H egy tetszőleges halmaz. Válasszuk ki és rögzítsük a H halmaz n∈ℕ+ darab (nem feltétlenül különböző) elemét (ai∈H, 1≤i≤n). Ekkor az
(a1, a2, ..., an)
véges elemsorozatot ("rendezett elem n-est") az ai elemek ismétléses permutációjának nevezzük.
Egy ismétléses permutációban két elemet felcserélve csak akkor kapunk az előzőtől különböző permutációt, ha a felcserélt elemek különbözőek.
Tegyük fel, hogy az
(a1, a2, ..., an)
ismétléses permutációban s≤n darab különböző elem van.
Jelöljük ezeket az elemeket bj (1≤j≤s) módon. Ezekre teljesül, hogy az (a1, a2, ..., an) permutációban
a b1 elem k1-szer ismétlődik (1≤k1≤n),
a b2 elem k2-szer ismétlődik (1≤k2≤n),
...,
a bs elem ks-szer ismétlődik (1≤ks≤n).
Mivel a permutációban összesen 'n' darab elem van, az egyes elemek ismétlődéseinek összegére k1+k2+...+ks=n
teljesül.
Ebben az esetben az 'n' elem összes k1, k2, ..., ks-ad rendű (különböző) ismétléses permutációjának száma
P
k1,k2,...,ks
n
=
n!
k1!*k2!*...*ks!
módon számítható ki.
Emeljük ki, hogy
's' értéke a különböző elemek számát adja meg,
'n' értéke pedig az ismétléses permutációban levő különböző "helyek" (vagy pozíciók) számát adja meg, amely csak ismétlés nélküli permutációk esetén egyezik meg a permutációban levő különböző elemek számával.
Ebben az esetben ugyanis
k1=k2=...=ks=1
miatt egyrészt s=n, másrészt pedig
Pn1,1,...,1,i=
n!=
Pn
teljesül.
Egy ismétléses permutáció elemeit a
{ (b1,k1),
(b2,k2), ... ,
(bn,kn) }
véges multihalmaz (vagy "zsák") segítségével adhatjuk meg, ahol a fenti jelölésnek megfelelően a
(bj,kj)
számpárok ("tupletek") azt jelölik, hogy a multihalmazban a bj elem pontosan kj≥0 gyakorisággal fordul elő (1≤j≤n), és a gyakoriságokra
k1+k2+...+kn=n
teljesül. Vegyük észre, hogy most megengedtük a gyakoriságokra a nulla értéket is (ez azonban 0!=1 miatt ugyanazt az eredményt adja az ismétléses permutációk számára, mint a fenti képlet).
Egy ismétléses permutációt a multihalmaz összes elemének a multihalmazban szereplő gyakorisággal történő kiválasztásával kaphatunk meg (az elemeket tetszőleges sorrendben választva).
A fentiekből következik, hogy
(1) az összes lehetséges multihalmaz számát 'n' elem 'n'-ed rendű ismétléses kombinációja adja meg;
(2) ha a multihalmaz összesen két elemet (s=2) tartalmaz k1>0 és k2>0 gyakorisággal, és az összes többi elem gyakorisága zérus (vagyis k1+k2=n teljesül), akkor 'n' elem k1 és k2 rendű ismétleses permutációja megegyezik 'n' elem k=k1 rendű (vagy 'n' elem k=k2=(n−k1) rendű) ismétlés nélküli kombinációjával, azaz
Pnk1,k2,i=
n!/(k1!*k2!)=
Cnk=
(nk)=
(nn−k)=
Cnn−k
teljesül.
A feladat egy lehetséges modellje: hányféleképpen állíthatunk össze 'k' darab fehér és (n−k) darab fekete golyóból egy sorozatot (permutáció), illetve hányféleképpen oszthatjuk fel az 'n' természetes számból álló (alap)halmazt egy 'k' elemű, és egy (n−k) elemű részhalmazra (kombináció)?
Például a
{ (1,2), (2,1), (3,2) }
multihalmaznak megfelelő számok, azaz az (1,2,3) számok 5 elemből álló (2,1,2) osztályú ismétléses permutációi a következőképpen állíthatók elő:
/* ismétléses permutációk, P5 (2,1,2) */
function szamlal(n) {
if(n==1) { s1++; }
else if(n==2) { s2++; }
else if(n==3) { s3++; }
}
function ervenyes(i,j,k,l,m) {
var b=true;
s1=0;s2=0;s3=0;
szamlal(i);
szamlal(j);
szamlal(k);
szamlal(l);
szamlal(m);
if(s1!=2 || s2!=1 || s3!=2) { b=false; }
return b;
}
var i,j,k,l,m;
var sorszam=0;
var s1=0; // '1' száma a permutációban
var s2=0; // '2' száma a permutációban
var s3=0; // '3' száma a permutációban
for(var i=1;i<=3;i++) {
for(var j=1;j<=3;j++) {
for(var k=1;k<=3;k++) {
for(var l=1;l<=3;l++) {
for(var m=1;m<=3;m++) {
if(ervenyes(i,j,k,l,m)) {
writeln("("+i+","+j+","+k+","+l+","+m+")");
sorszam++;
}
}
}
}
}
}
writeln();
writeln("a variációk száma: "+sorszam);
writeln("-----");
Megjegyzés: a fenti program az (1,2,3) számokból képzett 5 elemű, (2,1,2) osztályú ismétléses permutációkat úgy állítja elő, hogy előállítja az (1,2,3) számok összes 5-öd osztályú (vagy rendű) ismétléses variációit (ld. később), és ezekből kiszűri azokat az "érvényes" permutációkat, amelyekben pontosan 2 db 1-es, 1 db. 2-es és 2 db. 3-as szám szerepel.
A program futásának eredménye:
Variációk
Ismétlés nélküli variációk
Legyen H egy tetszőleges, 'n' elemű halmaz, és válasszuk ki ennek k∈ℕ+ darab különböző elemét (ai, aj∈H, ai≠aj, 1≤i<j≤k≤n); speciálisan megengedjük a k=1 (és k=n) esetet is. Ekkor az (a1, a2, ..., ak)
véges elemsorozatot az ai elemek egy ismétlés nélküli variációjának nevezzük.
Rögzített k∈ℕ+ elemszám esetén az n elem összes különböző k-ad osztályú ismétlés nélküli variációjának száma
V
k
n
= n*(n-1)*(n-2)*...*(n-k+1) =
n!
(n−k)!
módon számítható ki.
Vegyük észre, hogy k=n esetén (0!=1 miatt) éppen az ismétlés nélküli permutációk számát kapjuk (az ismétlés nélküli permutációk ilyen értelemben az ismétlés nélküli variációk speciális eseteként is felfoghatóak).
Például az (1,2,3,4) számok 3-ad osztályú ismétlés nélküli variációi a következőképpen állíthatók elő:
/* ismétlés nélküli variációk, V4,3 (1,2,3,4) */
var i,j,k;
var sorszam=0;
for(var i=1;i<=4;i++) {
for(var j=1;j<=4;j++) {
if(j==i) continue;
for(var k=1;k<=4;k++) {
if(k==i || k==j) continue;
writeln("("+i+","+j+","+k+")");
sorszam++;
}
}
}
writeln();
writeln("a variációk száma: "+sorszam);
writeln("-----");
A program futásának eredménye:
Ismétléses variációk
Legyen H egy tetszőleges, 'n' elemű halmaz, és válasszuk ki ennek k∈ℕ+ darab elemét úgy, hogy egy elemet többször is kiválaszthatunk (ai∈H, 1≤i≤k). Ekkor az (a1, a2, ..., ak)
véges elemsorozatot az ai elemek egy ismétléses variációjának nevezzük (mivel egy elemet többször is kiválaszthatunk, k>n is lehetséges).
Rögzített k∈ℕ+ elemszám esetén az 'n' elem összes különböző k-ad osztályú ismétléses variációjának száma
V
k, i
n
= nk
módon számítható ki.
Például az (1,2,3) számok 3-ad osztályú ismétléses variációi a következőképpen állíthatók elő:
/* ismétléses variációk, V3,3,i (1,2,3) */
var i,j,k;
var sorszam=0;
for(var i=1;i<=3;i++) {
for(var j=1;j<=3;j++) {
for(var k=1;k<=3;k++) {
writeln("("+i+","+j+","+k+")");
sorszam++;
}
}
}
writeln();
writeln("a variációk száma: "+sorszam);
writeln("-----");
A program futásának eredménye:
Kombinációk
Ismétlés nélküli kombinációk
Legyen H egy tetszőleges, 'n' elemű halmaz, és válasszuk ki ennek k∈ℕ darab különböző elemét (ai, aj∈H, ai≠aj, 1≤i<j≤k≤n) úgy, hogy nem számít a kiválasztott elemek sorrendje; speciálisan megengedjük a k=1 (és k=n) esetet is. Ekkor az { a1, a2, ..., ak }
véges elemhalmazt az ai elemek egy ismétlés nélküli kombinációjának nevezzük.
(Az ismétlés nélküli kombinációkat úgy is felfoghatjuk, hogy az ismétlés nélküli variációknál megismerteknek megfelelően kiválasztunk egy 'k' elemből álló elemsorozatot, és ezek lehetséges permutációi között nem teszünk különbséget. Ez számok esetében a legegyszerűbben úgy oldható meg, hogy a kiválasztott számokat növekvő sorrendben elrendezzük, ez ugyanis az azonos számokból álló variációk közül minden esetben csak azt az egy permutációt "hagyja meg", amelyben a számok rendezettek, és a többi permutációt kiszűri.)
Az ismétlés nélküli kombinációkat úgy képezzük, hogy tetszőlegesen kiválasztott 'k' különböző elem összes lehetséges (k! darab) permutációjához egy kijelölt permutációt rendelünk hozzá (ti. azt, amelyekben a számokat elrendezzük). Ezért ha 'k' különböző elemet egymás után, adott sorrendben választunk ki 'n' különböző elemből, akkor ismétlés nélküli kombinációk esetén a 'k' különböző elem összes lehetséges kiválasztásának számát osztanunk kell a k! értékkel.
Rögzített k∈ℕ elemszám esetén az n elem összes különböző k-ad osztályú ismétlés nélküli kombinációjának száma
C
k
n
=
n!
=
(
n
)
(n−k)!*k!
k
módon számítható ki, ahol az
(
n
)
=
n!
k
k!*(n−k)!
műveletet ("n alatt a k") az n és k nemnegatív egész számok ún. binomiális együtthatójának nevezzük.
Például az (1,2,3,4) számok 3-ad osztályú ismétlés nélküli kombinációi a következőképpen állíthatók elő:
/* ismétlés nélküli kombinációk, C4,3 (1,2,3,4) */
var i,j,k;
var sorszam=0;
for(var i=1;i<=4;i++) {
for(var j=i+1;j<=4;j++) {
for(var k=j+1;k<=4;k++) {
writeln("{"+i+","+j+","+k+"}");
sorszam++;
}
}
}
writeln();
writeln("a kombinációk száma: "+sorszam);
writeln("-----");
Vegyük észre, hogy a kombinációk egyes elemeinek kiválasztását végző 'for' ciklusok ciklusváltozóinak (i, j és k) kezdőértéke biztosítja, hogy az {i,j,k} alakú kombinációk mindegyikében i<j<k teljesüljön, vagyis az elemek a kombinációban növekvő sorrendben szerepeljenek.
A program futásának eredménye:
Ismétléses kombinációk
Legyen H egy tetszőleges, 'n' elemű halmaz, és válasszuk ki ennek k∈ℕ+ darab ai∈H elemét (1≤i≤k) úgy, hogy nem számít a kiválasztott elemek sorrendje, és egy elemet többször is kiválaszthatunk. Ekkor az { (a1,k1), (a2,k2), ... , (an,kn) }
véges multihalmazt (vagy "zsákot") a ki≥0 gyakorisággal előforduló ai elemek (1≤i≤n) egy ismétléses kombinációjának nevezzük. Mivel az ismétléses kombináció során pontosan 'k' darab elemet választunk, a zsákban levő elemek gyakoriságára minden választás esetén
k1+k2+k3+ ... +kn=k
teljesül (mivel egy elemet többször is kiválaszthatunk, k>n is lehetséges).
(Az ismétléses kombinációkat úgy is felfoghatjuk, hogy az ismétléses variációknál megismerteknek megfelelően kiválasztunk egy k elemből álló elemsorozatot, és ezek lehetséges ismétlésespermutációi között nem teszünk különbséget. Ez számok esetében a legegyszerűbben úgy oldható meg, hogy a kiválasztott számokat nem csökkenő sorrendben elrendezzük, ez ugyanis az azonos számokból álló variációk közül minden esetben csak azt az egy permutációt "hagyja meg", amelyben a számok nem csökkenő sorrendben állnak, és a többi permutációt kiszűri. Tehát például az első 'n' természetes szám k-ad osztályú ismétléses kombinációit a számokból képezhető 'k' elemű rendezett számsorozatok (szám n-esek) adják meg, amelyekben egy szám többször is előfordulhat.)
Rögzített k∈ℕ+ elemszám esetén az 'n' elem összes különböző k-ad osztályú ismétléses kombinációjának száma
C
k, i
n
=
C
n+k−1
n
=
(
n+k−1
)
k
módon számítható ki.
Egy
{ (a1,k1), (a2,k2), ... , (an,kn) }
ismétléses kombinációt kizárólag a ki≥0 gyakoriságok határoznak meg, ahol
k1+k2+...+kn=k
miatt nyilvánvalóan ki≤n is teljesül (1≤i≤n).
Az ismétléses kombináció az
(ai,ki)
elempárokból álló multihalmaz (1≤i≤n), amelyek sorrendje tetszőlegesen megválasztható. Rögzítsünk ezért egy meghatározott sorrendet (például úgy, hogy az (ai,ki) elempárokat az ai elemek szerint növekvő sorrendben elrendezzük).
Ezután kódoljuk az elempárokat a következőképpen:
(0) legyen i←1,
(1) az ai elemet helyettesítsük egy rögzített B értékkel és írjuk le,
(2) B után írjunk annyi X-t, amennyi ki értéke,
(3) legyen i←i+1 (azaz növeljük i értékét 1-gyel), és
(4) folytassuk az algoritmust az (1) lépésben, amíg i≤n fennáll.
Az algoritmus eredményeként minden ismétléses kombinációhoz kölcsönösen egyértelműen hozzárendeltünk egy B-vel kezdődő, a B és X karakterek csoportjaiból álló sorozatot, amelyben pontosan 'n' darab B és 'k' darab X érték található (ahol az i-dik Bután szereplő X karakterek száma meghatározza az i-dik elem ki gyakoriságát).
Az első B elemet változatlanul hagyva (n+k−1) darab elem marad, amelyekben (n−1) darab B és 'k' darab X elem ismétlődik. Ezeknek az elemeknek minden különböző ismétléses permutációja külcsönösen egyértelműen megfeleltethető 'n' elem egy 'k'-ad rendű ismétléses kombinációjának (és megfordítva).
Tehát az (n−1) darab B és 'k' darab X elemből álló sorozatok, vagyis összesen (n+k−1) elem összes (n−1) és k-ad rendű ismétléses permutációja
megadja az 'n' elem k-ad osztályú ismétléses kombinációinak számát. Ez a korábbiaknak megfelelően
(n+k−1)!/((n−1)!*k!)
ami éppen a bizonyítandó formulát adja
(vö. Cser et al. 1962: 458-459; Vilenkin 1987: 50-51).
Például az (1,2,3,4) számok 3-ad osztályú ismétléses kombinációi a következőképpen állíthatók elő:
/* ismétléses kombinációk, C4,3,i (1,2,3,4) */
var i,j,k;
var sorszam=0;
for(var i=1;i<=4;i++) {
for(var j=i;j<=4;j++) {
for(var k=j;k<=4;k++) {
writeln("{"+i+","+j+","+k+"}");
sorszam++;
}
}
}
writeln();
writeln("a kombinációk száma: "+sorszam);
writeln("-----");
Vegyük észre, hogy a kombinációk egyes elemeinek kiválasztását végző 'for' ciklusok ciklusváltozóinak (i, j és k) kezdőértéke biztosítja, hogy az {i,j,k} alakú kombinációk mindegyikében i≤j≤k teljesüljön, vagyis az elemek a kombinációban nem csökkenő sorrendben szerepeljenek.
A program futásának eredménye:
A fenti program eredményei formálisan "halmazok", de az ismétlődő elemek jelzik, hogy valójában multihalmazokat kaptunk. Ezeket például az alábbi programmal tudjuk megjeleníteni:
/* ismétléses kombinációk, C4,3,i (1,2,3,4) multihalmazként megjelenítve*/
function mh(x) {
var y=0;
if(x==i) y++;
if(x==j) y++;
if(x==k) y++;
return "("+x+","+y+")";
}
var i,j,k;
var sorszam=0;
for(var i=1;i<=4;i++) {
for(var j=i;j<=4;j++) {
for(var k=j;k<=4;k++) {
write("["+i+","+j+","+k+"] = {");
writeln(mh(1)+","+mh(2)+","+mh(3)+","+mh(4)+"}");
sorszam++;
}
}
}
writeln();
writeln("Az ismétléses kombinációk száma: "+sorszam);
writeln("-----");
A program futásának eredménye:
Gyakorló feladatok
(vö. Szabó 1996: 82-87)
(1) Hat kosárlabdacsapat körmérkőzést játszik egymással.
(1.1) Egyfordulós körmérkőzés esetén hányféle sorrendben végezhetnek a csapatok?
Megoldás: P6=6!
(1.2) Egyfordulós körmérkőzés esetén hány mérkőzést jelent ez?
Megoldás: C62=
(62)=
6!/(2!*4!)=15
(1.3) Kétfordulós körmérkőzés esetén hány mérkőzést jelent ez?
Megoldás: V62=2*C62=6*5=2*15=30
(2) Hány 19-cel kezdődő, ötjegyű szám készíthető az {1,3,5,7,9} számjegyekből, ha
(2.1) a számok képzésénél egy számjegy csak egyszer szerepelhet?
Megoldás: P(5−2)=3!
(2.2) a számok képzésénél egy számjegy akárhányszor szerepelhet?
Megoldás: V53,i=53=125
(3) Hány páros, négyjegyű szám képezhető az {1,2,3,4} számjegyekből, ha
(3.1) minden számjegy csak egyszer szerepelhet?
(3.2) egy számjegy akárhányszor szerepelhet?
(4) Hány 3-mal osztható, négyjegyű szám képezhető az {1,2,3,4} számjegyekből, ha
(4.1) minden számjegy csak egyszer szerepelhet?
Megoldás: 0 (mivel 1+2+3+4=10 nem osztható 3-mal)
(4.2) egy számjegy akárhányszor szerepelhet?
(5) Hány 6-tal osztható, négyjegyű szám képezhető az {1,2,3,4} számjegyekből, ha
(5.1) minden számjegy csak egyszer szerepelhet?
(5.2) egy számjegy akárhányszor szerepelhet?
(6) Hány 10-zel osztható, négyjegyű szám képezhető a {0,1,2,3,4} számjegyekből, ha
(6.1) minden számjegy csak egyszer szerepelhet?
Megoldás: V43=4*3*2=24
(6.2) egy számjegy akárhányszor szerepelhet?
Megoldás: 4*V52,i=4*5*5=100
(7) Egy 6 főből álló baráti társaság az étteremben egy kör alakú asztal körül elhelyezett 6 széken akar helyet foglalni.
Hányféleképpen történhet ez meg, ha két elhelyezkedést akkor és csak akkor tekintünk különbözőnek, ha a társaságnak van legalább egy olyan tagja, akinek vagy a bal oldali, vagy a jobb oldali szomszédja a két esetben különböző?
Megoldás: P(6−1)=5!
(8) 10 ember ül le egy kerek asztal mellé. Hányféleképpen helyezkedhetnek el, ha azt akarjuk, hogy
(8.1) Kovács és Lakatos feltétlen egymás mellett üljön?
(8.2) Kovács és Lakatos soha ne üljön egymás mellett?
(9) 10 ember ül le egymás mellé egy egyenes asztal egyik oldalán. Hányféleképpen helyezkedhetnek el, ha azt akarjuk, hogy
(9.1) Kovács és Lakatos feltétlen egymás mellett üljön?
(9.2) Kovács és Lakatos soha ne üljön egymás mellett?
(10) 10 ember ül le egymás mellé egy egyenes asztal mindkét oldalán (az asztalfőn egyik oldalon sem ül senki). Hányféleképpen helyezkedhetnek el, ha azt akarjuk, hogy
(10.1) Kovács és Lakatos feltétlen egymás mellett üljön?
(10.2) Kovács és Lakatos soha ne üljön egymás mellett?
(11) 6 piros, 3 fehér, 2 kék golyót hányféleképpen lehet egymás mellé helyezni, hogy a hat piros golyó nem kerüljön egymás mellé?
(12) Hány nyolcjegyű szám képezhető a (0,0,0,0,1,1,1,1) számjegyekből?
Megoldás: P73,4,i=7!/(3!*4!)=35
(13) Hány különböző gyöngysort lehet készíteni 20 gyöngyszemből, ha
(13.1) a gyöngysor két végét nem kötjük össze, és 10 fehér és 10 kék gyöngyünk van?
(13.2) a gyöngysor két végét nem kötjük össze, és 10 fehér, 5 kék és 5 piros gyöngyünk van?
(13.3) a gyöngysor két végét összekötjük, és 5 fehér és 15 kék gyöngyünk van?
(13.4) a gyöngysor két végét összekötjük, és 10 fehér, 5 kék és 5 piros gyöngyünk van?
(14) Az {1,2,3,...,14,15} számokat sorozatba rendezzük. Hány olyan eset van, amelyben az {1,2} számok csökkenő sorrendben kerülnek egymás mellé?
(15) 10 tanuló között hányféleképpen lehet kiosztani 3 különböző tárgyat, ha egy tanuló több tárgyat is kaphat?
(16) Hány olyan hatjegyű szám van, amelynek minden számjegye 6-nál nagyobb és 9-nél kisebb?
(17) Hány olyan ötjegyű szám van, amelynek a második és a harmadik jegye 3-as, és a szám 5-tel osztható?
(18) 15 betűből és 10 számból autórendszámot készítünk úgy, hogy a rendszámban először 3 betű, majd 3 számjegy szerepeljen (pl. ABC 123). Hány autót tudunk így megkülönböztetni?
(19)
Egy dobókockával ötször dobunk egymás után. Hányféle dobássorozat lehetséges?
Megoldás: V65,i=65=7776
(20) Két kockával dobva hány esetben kapunk összesen legalább 8-at?
(21) Egy udvarban 10 kacsa és 24 tyúk van.
(21.1) Egy jó ebédet akarunk főzni. Hányféleképpen választhatunk ki egy kacsát és egy tyúkot?
Megoldás: C101*C241=
240
(21.2) Egy jó és bőséges ebédet akarunk főzni. Hányféleképpen választhatunk hozzá ki két kacsát és két tyúkot,
A fenti feladat példa hipergeometrikus eloszlásra N=34, s=10, n=4 és k=2 paraméterekkel, ahol az összes eset számát
CNn=
(Nn)=
(344)=
(34*11*4*31)=
46376
adja meg.
Ebben az esetben az összes eset számát
V344=
34!/(34−4)!=
34*33*32*31=
1113024
adja meg.
(21.2) Főzés előtt meg szeretnénk vizsgálni a háziállatok minőségét. Hányféleképpen választhatunk ki két kacsát és két tyúkot úgy, hogy egy kacsát vagy egy tyúkot többször is kiválaszthatunk (azaz minden véletlen kiválasztás után "visszatesszük" a kiválasztott madarakat),
A fenti feladat példa binomiális eloszlásra N=34, s=10, n=4 és k=2 paraméterekkel, ahol az összes eset számát
Nn=
344=
1336336
adja meg.
(22) Egy biológiadolgozatban 10 kérdés szerepel. Az egyes válaszokat kérdésenként {A,B,C,D,E} betűk jelölik (minden kérdésre öt lehetséges választ sorolunk fel).
(22.1) Ha minden kérdésre pontosan egy jó választ adhatunk, hányféle különböző választássorozat lehetséges?
(22.2) Ha minden kérdésre legalább egy és legfeljebb négy jó választ adhatunk (amerikai stílusú teszt), hányféle különböző választássorozat lehetséges?
(23) Hányféleképpen lehet 90 számból 5 számot kihúznunk (lottóhúzás), ha a számok sorrenje nem számít?
(24) 100 darab tévékészülék köztt 10 hibás (selejtes) darab van. Hányféleképpen tudunk 15 készüléket úgy kiválasztani, hogy a kiválasztott készülékek között
(24.1) ne legyen hibás?
(24.2) 1 hibás legyen?
(24.3) 3 hibás legyen?
(24.4) legfeljebb 3 hibás legyen?
(25) 5 lány és 3 fiú röplabdázni szeretne. Hányféleképpen alkothatunk két, négyfős csapatot, ha azt szeretnénk, hogy mindkét csapatban legyen legalább egy fiú?
(26) Egy csomag 52 lapos franciakártya csomagból 10 lapot húzunk ki. Hány esetben lesz ezek között
(26.1) legalább egy király?
(26.2) pontosan egy király?
(26.3) legalább két király?
(26.4) pontosan két király?
(27) Egy rekeszben 20 üveg sor van. 15 üvegben világos sör, 5 üvegben barna sör van. Hányféleképpen választhatunk ki 6 üveg sört úgy, hogy pontosan két barna sörünk legyen?
(28) Egy osztályban 14 fiú és 16 lány van. Hányféleképpen lehet 4 fiút és 4 lányt kiválasztani, akik együtt mennek moziba?
(29) Egy urnában húsz cédula van 1-től 20-ig megszámozva. Húzzunk ki 5 cédulát úgy, hogy minden húzás után a kihúzott cédulát visszatesszük. Hány esetben lesz a kihúzott legkisebb szám nagyobb 6-nál?
(30) Egy 10 elemű halmaznak hány 3 elemű részhalmaza van?
Eseményalgebra
A valószínűségszámítás ún. véletlen tömegjelenségekkel foglalkozik, amelyek hasonló körülmények között (legalábbis elvileg) tetszőleges sokszor megfigyelhetők, vagy kísérletek formájában bármikor kiválthatóak vagy előállíthatóak, és ezáltal vizsgálhatóak.
A vizsgált véletlen tömegjelenség egy bekövetkezését a továbbiakban kísérletnek nevezzük, egy kísérlet lehetséges, egymást kölcsönösen kizáró kimeneteleit elemi eseményeknek, az elemi események összességét pedig eseménytérnek nevezzük.
Ha egyazon véletlen jelenség vizsgálatakor n darab kísérletet végzünk el, (n darabos) mintavételről beszélünk.
Például ha egy kockával dobunk, kísérletről beszélhetünk, ahol az eseményteret alkotó elemi események a dobások lehetséges értékei (vagyis ekkor az eseményteret hat elemi esemény alkotja). Ha egymás után 10-szer dobunk, 10 darabos mintavételt végeztünk.
Jelöljük az eseménytért
Ω
módon.
Az eseménytér
A⊆Ω
részhalmazait (véletlen) eseményeknek nevezzük.
A következő eseményeket fogjuk megkülönböztetni:
– az A⊆Ω esemény lehetetlen esemény, ha egyetlen elemet sem tartalmaz, azaz A=∅ (vagy |A|=0);
– az A⊆Ω esemény elemi esemény, ha pontosan egy elemet tartalmaz, azaz Aω={ ω∈Ω }
(megjegyzés: ha nem okoz félreértést, az elemi eseményekre az
Aω={ ω∈Ω }
halmaz helyett egyszerűen ω∈Ω módon hivatkozunk);
– az A⊆Ω esemény összetett esemény, ha egynél több elemet tartalmaz, azaz ∣A∣>1 teljesül;
– az A⊆Ω esemény biztos esemény, ha Ω összes elemét tartalmazza, azaz A=Ω teljesül.
Az eseményalgebra alapvető fogalma az események bekövetkezése:
Egy kísérlet során pontosan egy elemi esemény következik be.
Tegyük fel, hogy az
Aω={ ω }
elemi esemény bekövetkezett.
Ekkor egy A={ ω1, ω2, ..., ωk }
összetett esemény akkor és csak akkor következik be, ha
Aω⊆A, azaz ω∈A teljesül.
Például ha egy kockával dobunk, az elemi események halmaza
Ω = {ω1, ω2, ..., ω6}
ahol ωi jelenti azt az elemi eseményt, hogy a kockával 'i'-t dobtunk (1≤i≤6).
Ekkor például az
A = {a dobás eredménye páros szám} = {ω2, ω4, ω6}
összetett esemény pontosan akkor következik be, ha az ω2, ω4 és ω6 (egymást kizáró) elemi események közül az egyik bekövetkezik.
Ha az A, B⊆Ω események egyenlőek (A=B), akkor A pontosan akkor következik be, amikor B bekövetkezik. Az A⊆Ω esemény
B=Ω∖A
kiegészítő vagy komplementer eseménye pontosan akkor következik be, amikor A nem következik be.
A B⊆Ω esemény maga után vonja az A⊆Ω eseményt (másképpen a B eseményből következik az A esemény), ha B⊆A teljesül. Ebben az esetben ha B bekövetkezik, akkor A is bekövetkezik (de ha B nem következik be, akkor ebből A bekövetkezésére vonatkozóan semmilyen következtetést nem tudunk levonni).
A "B-ből következik A" relációt például a logikában megszokott módon B⊃A vagy B⇒A formában jelölhetjük. A valószínűségszímítás szakirodalmában szokásos a B⊂A jelölés is, de a jelölések inkonzisztenciájának elkerülése miatt a halmazelméletben megszokott B⊆A jelölés sokkal jobb választásnak tűnik.
Az eseményalgebrában az események közötti műveleteket mint (rész)halmazok közötti műveleteket értelmezzük, és a következőképpen nevezzük, ill. jelöljük:
– az A, B⊆Ω események összege az
A+B = { ω∈Ω | ω∈A ∨ ω∈B} esemény;
– az A, B⊆Ω események szorzata az
A*B = { ω∈Ω | ω∈A ∧ ω∈B} esemény (megjegyzés: az A és B események szorzatát a szakirodalomban AB módon is jelölik);
– az A, B⊆Ω események különbsége az
A−B = { ω∈Ω | ω∈A ∧ ω∉B} esemény.
(Két esemény különbsége A−B=A*B módon is kifejezhető.)
Az A, B⊆Ω események egymást (kölcsönösen) kizáró események, ha
A*B=∅
teljesül.
Az A1, A2, ..., Ak⊆Ω események teljes eseményrendszert alkotnak, ha
– A1+A2+ ... +Ak=Ω és
– Ai*Aj=∅ (1≤i<j≤k)
teljesül. A definícióból következik, hogy egy teljes eseményrendszert alkotó események közül mindig pontosan egy következik be.
Intuitíven két eseményt függetlennek nevezünk, ha az egyik bekövetkezése "nem befolyásolja" a másik bekövetkezését. Azonban pusztán eseményalgebrai eszközökkel ezt nem tudjuk egzakt módon értelmezni.
A valószínűség fogalma
Ha egy kísérletet n-szer megfigyelünk vagy végrehajtunk, és a kísérlet eseményalgebrai modelljében az A esemény k-szor következik be, a kA értéket az A esemény gyakoriságának, az
ηA
=
kA
n
számot az A esemény relatív gyakoriságának nevezzük. A valószínűségszámítás jelentőségét az a gyakorlati tapasztalat adja, hogy a véletlen tömegjelenségek esetében a relatív gyakoriság egy adott (0 és 1 közötti) számérték körül ingadozik.
Jelöljük azt az értéket, amely körül az ηA relatív gyakoriság ingadozik, P(A)-val.
Az alábbiakban ezt az értéket fogjuk intuitíven az A esemény valószínűségének tekinteni. A valószínűség matematikai fogalmát azonban axiomatikusan vezetjük be.
A valószínűségre vonatkozó axiómák a következők (A. N. Kolmogorov nyomán, 1933):
(1) Legyen Ω egy eseménytér. Az eseménytér minden A⊆Ω eseményéhez hozzárendelünk egy P(A) valós számot, amelyet az esemény valószínűségének nevezünk.
A valószínűség 0 és 1 közötti érték, azaz bármely A⊆Ω esemény esetén 0≤P(A)≤1 teljesül.
(2) A biztos esemény valószínűsége 1, azaz P(Ω)=1 teljesül.
(3) Ha A1, A2, ..., Ak egymást páronként kizáró események (azaz Ai*Aj=∅, 1≤i<j≤k), akkor
P(A1+A2+ ... +Ak) =
P(A1)+P(A2)+ ... +P(Ak)
teljesül.
Megjegyzés: a továbbiakban a "valószínűség" helyett néha használni fogjuk a rövidebb "valség" megnevezést is.
Az axiómákból számos fontos összefüggés levezethető.
Legyenek A, B⊆Ω tetszőleges események. Ekkor teljesülnek az alábbi összefüggések:
A lehetetlen esemény valószínűsége 0, azaz P(∅)=0 teljesül.
Ha az A1, A2, ..., Ak⊆Ω események teljes eseményrendszert alkotnak, akkor P(A1)+P(A2)+ ... +P(Ak)=1 teljesül.
Egy esemény és a komplementere teljes eseményrendszert alkotnak, tehát P(A)+P(A)=1 teljesül.
P(A)=1−P(A)
P(A*B)+P(A*B)=P(A)
P(A−B)=P(A*B)=P(A)−P(A*B)
Ha B⊆A teljesül, akkor P(A−B)=P(A)−P(B) teljesül.
P(A+B)=P(A)+P(B)−P(A*B)
Az utolsó összefüggés levezetése:
P(A+B)=P(A−B)+P(B−A)+P(A*B), de mivel
P(A−B)=P(A)−P(A*B) és
P(B−A)=P(B)−P(A*B) teljesül, ezért
P(A+B)=P(A)−P(A*B)+P(B)−P(A*B)+P(A*B), ezt egyszerűsítve
P(A+B)=P(A)+P(B)−P(A*B), q.e.d.
Események függetlensége
Az A, B⊆Ω eseményeket függetleneknek nevezzük, ha
P(A*B) = P(A)*P(B)
teljesül. Ebből következik, hogy a biztos és a lehetetlen esemény minden eseménytől független; továbbá az, hogy az egymást kizáró és pozitív valségű események nem lehenek függetlenek.
Legyenek A, B⊆Ω események, és legyen B egy pozitív valószínűségű esemény (azaz P(B)>0 teljesül). Tegyük fel, hogy a B esemény bekövetkezett; ilyen feltétel mellett az A esemény bekövetkezését jelöljük A|B-vel.
Az A|B esemény az A esemény leszűkítését jelenti az Ω|B eseménytérre, azaz
B = { ω1, ω2, ..., ωm }
esetén
A|B = { ω∈A | ω∈ B }
teljesül. Ez értelemszerűen megfelel az Ω eseménytéren az
A*B = { ω∈Ω | ω∈A ∧ ω∈ B }
eseménynek.
Megjegyzések:
(1) Legyen az Ω eseménytéren a B esemény valsége P(B) (a B esemény az Ω|B eseménytéren a biztos esemény, tehát a B esemény valsége PB=1.) Ekkor az Ω|B eseménytér elemi eseményeinek valsége
PB(ω)=P(ω)/P(B),
mivel az Ω|B eseménytéren az elemi események valségének az összege 1 kell, hogy legyen. (Feltételezzük, hogy a B esemény bekövetkezése nem befolyásolja az ωi elemi események valségét.)
(2) Az ΩB=Ω|B eseménytérre való leszűkítés minden A⊆Ω eseménynek az
A*B⊆Ω ↔ A|B⊆ΩB
eseményt felelteti meg. Ebből azonban nyilvánvalóan nem következik az, hogy
PB(A|B)=P(A*B),
mivel az A|B és A*B eseményeket, valamint a PB és P valószínűségeket más eseménytéren értelmezzük.
Az A esemény B eseményre vonatkozó feltételes valószínűsége alatt az A|B eseménynek az Ω|B eseménytéren vett valószínűségét, azaz PB(A|B)-t értjük, és
PB(A|B)=P(A*B)/P(B)
módon definiáljuk.
(Ez a definíció teljes összhangban van a valószínűség klasszikus kiszámítási módjával (ld. később; vö. Csatlósné 1996: 173-174). Ez azonban hallgatólagosan feltételezi, hogy az Ω eseménytér leszűkítése az ΩB eseménytérre, azaz a B esemény megfigyelése nem változtatja meg a valószínűségi viszonyokat.)
A továbbiakban, ha nem okoz félreértést, PB(A|B) helyett egyszerűen P(A|B)-t írunk.
A feltételes valószínűség definíciójából
P(A*B)=P(A|B)*P(B)
következik. Ebből viszont az következik, hogy független események esetén (P(A*B)=P(A)*P(B) és P(B)>0 miatt)
P(A|B)=P(A)
teljesül.
Tekintsük a következő példát: legyen 3 tyúkunk (ezek halmaza {A,B,C}) és 2 kacsánk (ezek halmaza pedig {X,Y}). Válasszunk két állatot egymás után úgy, hogy a kiválasztott állatot mindig visszatesszük. Mivel egymás után választunk, a kiválasztás sorrendje számít, azaz pl. (A,X) és (X,A) különböző elemi események. Ezért összesen 5*5=25 lehetséges elemi eseményünk van.
Legyen például a 'D' esemény az, hogy egy tyúkot és egy kacsát választottunk (a kiválasztás sorrendjétől függetlenül). A 'D' esemény 3*2+2*3=12 választás esetén következhet be, vagyis P(D)=12/25.
Ezek után legyen az 'E' esemény az, hogy elsőre tyúkot választottunk. Az 'E' esemény 3*5=15 választás esetén következhet be, vagyis P(E)=15/25=3/5.
Az 'F' esemény pedig legyen az, hogy az első kiválasztott állat megegyezik a másodikkal (azaz a két választás megegyezik). Az 'F' esemény 5 választás esetén következhet be, vagyis P(F)=5/25=1/5.
Mivel az E*F esemény nyilvánvalóan 3 választás esetén következhet be, ezért P(E*F)=3/25. De P(E)=3/5 és P(F)=1/5 miatt P(E*F)=P(E)*P(F), vagyis az 'E' és az 'F' események egymástól függetlenek.
Vizsgáljuk meg az E|F feltételes eseményt. Mivel ΩF 5 elemi eseményből áll, amiből az (A,A), (B,B) és (C,C) elemi események alkotják az E|F eseményt, ezért P(E|F)=3/5, ami megegyezik P(E)-vel.
Vizsgáljuk meg az F|E feltételes eseményt is. Mivel ΩE 15 elemi eseményből áll, amiből az (A,A), (B,B) és (C,C) elemi események alkotják az F|E eseményt, ezért P(E|F)=3/15=1/5, ami megegyezik P(F)-vel.
Írjuk a P(A*B)=P(A|B)*P(B) képletbe az A*B esemény helyett az
A2*A1
eseményt, ekkor
P(A2*A1)=P(A2|A1)*P(A1)
adódik. Ezt három eseményre általánosítva
P(A3*A2*A1) =
P(A3|A2*A1)*P(A2*A1)
miatt
P(A3*A2*A1) =
P(A3|A2*A1)*P(A2|A1)*P(A1)
adódik (és ez könnyen tovább általánosítható akár 'n' eseményre is). A képlet egy lehetséges alkalmazására később egy példát is adunk.
Ha az A, B⊆Ω események függetlenek, akkor
P(A*B)=P(A)*P(B)
teljesül, tehát a feltételes valószínűség definíciójából
PB(A|B)=P(A) és PA(B|A)=P(B)
következik.
Tegyük fel, hogy a B1, B2, ..., Bk⊆Ω események teljes eseményrendszert alkotnak, és az A⊆Ω eseményre ismertek a P(A|Bi) feltételes valószínűségek (1≤i≤k). Ekkor
P(A) =
k
Σ
i=1
P(A|Bi)*P(Bi)
teljesül (a teljes valószínűség tétele).
Tegyük fel, hogy a B1, B2, ..., Bk⊆Ω események teljes eseményrendszert alkotnak, P(Bi)>0 (1≤i≤k), A⊆Ω tetszőleges esemény, amelyre P(A)>0,
és ismertek a P(A|Bi) feltételes valószínűségek (1≤i≤k). Ekkor
P(A) =
k
Σ
i=1
P(A|Bi)*P(Bi)
felhasználásával a P(Bj|A) feltételes valószínűségek (1≤j≤k) kiszámíthatók
P(Bj|A) =
P(A|Bj)*P(Bj)
P(A)
módon (Bayes tétele).
Tekintsük az alábbi példát (Bíró-Vincze 2010: 364-365).
Egy üzemben egy terméket négy különböző géppel állítanak elő.
Az első gép a termékek 20 százalékát, a második és harmadik 25 százalákát, a negyedik pedig 30 százalékát álltja elő.
Emellett még azt is tudjuk, hogy az első gép selejtszázaléka 2%, a másodiké 1.5%, a harmadiké 2.5%, a negyediké pedig 1%.
Jelentse 'A' azt az eseményt, hogy egy kiválasztott termék selejtes. Keressük 'A' valségét, továbbá annak a valségét, hogy a kiválasztott terméket a negyedik gép gyártotta.
(1) Ha Bi jelenti azt, hogy a kihúzott terméket az i-dik gép állította elő (1≤i≤4), akkor
P(B1)=0.20,
P(B2)=0.25,
P(B3)=0.25,
P(B4)=0.30
teljesül.
(2)
Mivel az első gép selejtszázaléka 2% (=0.02), a másodiké 1.5% (=0.015), a harmadiké 2.5% (=0.025), a negyediké 1% (=0.01), ezért az 'A' selejtes termék kihúzásának feltételes valsége
P(A|B1)=0.020,
P(A|B2)=0.015,
P(A|B3)=0.025,
P(A|B4)=0.010
gépenként.
(3) A fentieket felhasználva az 'A' selejtes termék valségére a teljes valószínűség tétele alapján
P(A) =
P(A|B1)*P(B1) +
P(A|B2)*P(B2) +
P(A|B3)*P(B3) +
P(A|B4)*P(B4) = 0.017 adódik.
(4) Annak a valsége, hogy az 'A' esemény teljesülése mellett a kiválasztott selejtes terméket a negyedik gép gyártotta, a Bayes-tétel alapján számítható ki
P(B4|A) = P(A|B4)*P(B4) / P(A) ≈ 0.176
módon.
Klasszikus valószínűségi mező
Az Ω = { ω1, ω2, ..., ωn } véges, n elemből álló eseményteret és a rajta értelmezett
P : 2Ω → [0,1]⊆ℝ
valószínűséget klasszikus valószínűségi mezőnek nevezzük, ha minden elemi esemény azonosan valószínű, azaz P(ωi)=P(ωj) (0≤i<j≤n) teljesül.
Ha Ω klasszikus valószínűségi mező, amelyre ∣Ω∣=n, akkor minden ω∈Ω elemi eseményre P(ω)=1/n teljesül.
Ha pedig
A={ ω1, ω2, ..., ωk }⊆Ω
tetszőleges esemény, amelyre ∣A∣=k, akkor az A esemény valószínűsége
P(A)
=
k
=
(kedvező esetek száma)
n
(lehetséges esetek száma)
módon számítható ki. (Ez a valószínűségek ún. klasszikus vagy kombinatorikus kiszámítási módja.)
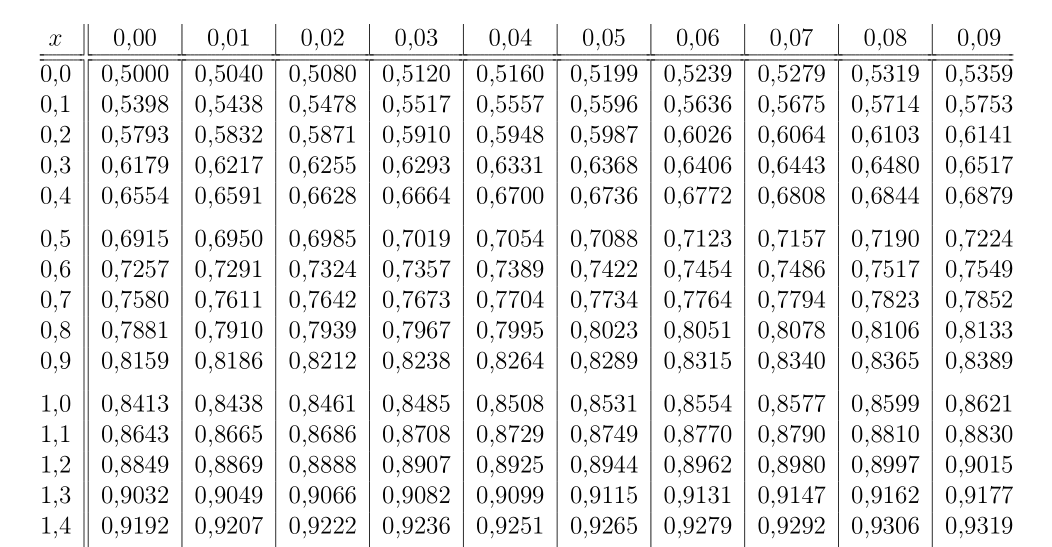
Az előzőek alkalmazására tekintsük a következő példát. Egy 32 lapos magyar kártyából egymás után három lapot húzunk (visszatevés nélkül). Számítsuk ki annak a valségét, hogy az első kihúzott lap hetes lesz (A1), a második kilences lesz (A2), és a harmadik hetes lesz (A3)? (Solt 1971: 134-135). Első megoldás:
(1) Mivel a 32 lapos magyar kártyában 4 db. hetes van, ezért a valség klasszikus kiszámítási módja alapján
P(A1)=4/32=1/8 adódik.
(Ha a klasszikus
Ω={(ωi,ωj,ωk) | 1≤i,j,k≤32}
eseménytérben minden elemi esemény azonos 32*32*32 valségű, akkor ebben az esetben is
P(A1)=4*32*32/(32*32*32)=1/8
adódik.)
(2) Mivel a 32 lapos magyar kártyában 4 db. kilences van, ezért a hetes kihúzása (A1) után a valség klasszikus kiszámítási módja alapján
P(A2|A1)=4/31 adódik.
(3) Mivel a 32 lapos magyar kártyában 4 db. hetes van, ezért a hetes és a kilences kihúzása (A1*A2) után a valség klasszikus kiszámítási módja alapján
P(A3|A1*A2)=3/30=1/10 adódik.
Tehát a keresett valószínűségre
P(A3*A2*A1) =
P(A3|A2*A1)*P(A2|A1)*P(A1) = (1/10)*(4/31)*(1/8) = 1/620
adódik. Második megoldás:
A valség klasszikus kiszámítási módja alapján a kedvező esetek száma
k=4*4*3,
az összes eset száma pedig
n=32*31*30,
amiből közvetlenül adódik a
P=k/n=1/620
valószínűség.
Egy fontos kiegészítés az előző példa megoldásához.
A három húzásnak megfelelő eseménytér az
Ω=Ω1xΩ2xΩ3
direkt szorzatnak felel meg. Legyen A∈Ω a három húzásnak megfelelő esemény, az egyes húzásoknak megfelelő eseményeket pedig jelöljük
A1∈Ω1,
A2∈Ω2,
A3∈Ω3
módon. Ekkor alapvető feltételezés az, hogy mivel az egyes húzásokat egymástól függetleneknek tekintjük,
P(A)=P(A1)*P(A2)*P(A3)
teljesül.
Valójában ilyenkor az
A3*A2*A1,
valamint az
A2|A1 és
A3|A2*A1
"feltételes" események pusztán formális jelölések, mivel az A1, A2 és A3 eseményeket más-más eseménytereken értelmezzük.
Az előző húzások következményeit az egyes húzásoknak megfelelő
Ω1, Ω2 és Ω3
eseményterek meghatározásakor vettük figyelembe.
Egy másik példa a következő. Egy kockadobás során jelölje 'A' azt az eseményt, hogy 6-nál kisebbet dobunk, azaz legyen
A={1,2,3,4,5}.
Másrészt jelölje 'B' azt az eseményt, hogy páros számot dobunk, azaz
B={2,4,6}.
Mekkora a valószínűsége annak, hogy ha páros számot dobunk, akkor az eredmény 6-nál kisebb lesz? (Bíró-Vincze 2010: 360) Megoldás:
A valség klasszikus kiszámítási módja alapján
P(B)=1/2 és P(A*B)=2/6=1/3, ezért a feltételes valség definíciója alapján a keresett valségre
P(A|B)=P(A*B)/P(B)=2/3 adódik.
(A feladat értelmezésekor először leszűkítettük az eseményteret a páros számokra, és feltettük, hogy ezek azonos valószínűségű elemi eseményeket jelentenek. Figyeljük meg, hogy a következő valószínűségeloszlás (ld. később) mellett
P(1)=0, P(2)=1/3, P(3)=0, P(4)=1/3, P(5)=0, P(6)=1/3
P(A*B)=P(2)+P(4)=2/3 adódik, vagyis ugyanarra a megoldásra jutunk.)
A feladat megfordítása:
A feladat értelmezésekor nagyon fontos, hogy melyik az az esemény, amelynek alapján a feltételes valséget képezzük. Ha ugyanis annak a valségét keressük, hogy ha 6-nál kisebb számot dobunk (A), akkor az eredmény páros lesz (B), más eredményre jutunk.
A valség klasszikus kiszámítási módja alapján
P(A)=5/6 és P(A*B)=2/6, ezért a keresett valségre a feltételes valség definíciója alapján
P(B|A)=P(A*B)/P(A)=2/5 adódik.
(A feladat értelmezésekor először leszűkítettük az eseményteret a 6-nál kisebb számokra, és feltettük, hogy ezek azonos valószínűségű elemi eseményeket jelentenek. Figyeljük meg, hogy a következő valószínűségeloszlás (ld. később) mellett
P(1)=1/5, P(2)=1/5, P(3)=1/5, P(4)=1/5, P(5)=1/5, P(6)=0
P(A*B)=P(2)+P(4)=2/5 adódik, vagyis ugyanarra a megoldásra jutunk.)
Kiegészítés:
Ha annak a valségét keressük, hogy páros és 6-nál kisebb számot fogunk dobni, a valségre a klasszikus kiszámítási mód alapján (feltéve, hogy minden dobás azonosan valószínű) egyszerűen
P(A*B)=2/6=1/3
adódik.
Klasszikus valószínűségeloszlások
Legyen
A1, A2, ..., Ak⊆Ω
teljes eseményrendszer. A teljes eseményrendszer valószínűségeinek sorozatát valószínűségeloszlásnak (vagy ha nem okoz félreértést, egyszerűen eloszlásnak) nevezzük (Rényi 1973: 83). Ennek megfelelően a
p1=P(A1), p2=P(A2), ..., pk=P(Ak)
valószínűségek sorozata egy valószínűségeloszlás, amelyre
k
Σ
i=1
pi
= 1
teljesül.
Korábban láttuk, hogy ha az
Ω = { ω1, ω2, ..., ωn }
véges eseménytér klasszikus valószínűségi mező, akkor az
ω1, ω2, ..., ωn
elemi események valószínűségeire
p1 = p2 = ... = pn = 1/n
teljesül. Ilyenkor egyenletes eloszlásról beszélünk.
Nézzünk meg két típusfeladatot, amelyek a gyakorlatban jól használható valószínűségeloszlásokhoz vezetnek.
visszatevés nélküli mintavétel
Legyen 'N' darab termékünk, és legyen ezek között 's' darab selejt (1≤s≤N). Vegyünk a termékekből egy 'n' elemű mintát (1≤n<<N) egyszerre vagy egymás után, de visszatevés nélkül. Határozzuk meg annak a valségét, hogy ezek között 'k' darab selejt lesz (0≤k≤s, 0≤k≤n) (Reimann-Tóth 1985: 26-27). A megoldás:
P(k)
=
(
s
)
(
N−s
)
k
n−k
(
N
)
n
(a) Ha az 'n' elemű minta elemeit egyszerre ("közvetlenül") vesszük ki (vagyis a kiválasztott elemek sorrendje nem számít), a képlet a valség klasszikus kiszámítási módja alapján a következőképpen kapható meg:
– a mintában 'k' darab különböző selejtes termék van, amelyeket az összes 's' darab selejtes termékből választunk; a kiválasztott selejtek sorrendje nem lényeges, ezért az összes kiválasztás számát 's' k-ad rendű ismétlés nélküli kombinációja adja, vagyis k1=(sk);
– az 'n' elemű mintában (n−k) darab különböző nem selejtes termék van; ezeket az összes (N−s) darab nem selejtes termékből választjuk ki úgy, hogy a kiválasztott termékek sorrendje nem lényeges, ezért az összes ilyen kiválasztás számát (N−s) (n−k)-ad rendű ismétlés nélküli kombinációja adja, vagyis k2=(N−sn−k);
– minden lehetséges 'k' elemű selejtcsoporthoz tartozhat minden lehetséges (n−k) elemű nem selejtes termékcsoport; az összes variációs lehetőséget a kiválasztások számának szorzata adja, vagyis k1*k2;
– a kedvező esetek száma tehát
(sk)*(N−sn−k);
– az 'n' elemű mintában különböző termékek vannak, és ezek sorrendje nem lényeges, ezért az összes minta (az összes eset) számát 'N' elem n-ed rendű ismétlés nélküli kombinációja adja, vagyis (Nn);
– ha a kedvező esetek számát elosztjuk az összes esetek számával, a fenti képlet adódik.
(b) Ha egyenként, visszatevés nélkül vesszük ki a mintaelemeket (és a kiválasztott elemek sorrendje számít), akkor a következőképpen számolhatunk:
(1) Ha először egymás után 'k' darab selejtet húzunk, akkor ezt
k1=s!/(s−k)!
módon tehetjük meg (ismétlés nélküli variáció);
(2) Ha ezután egymás után (n−k) darab minőségi (nem selejtes) terméket húzunk, akkor ezt
k2=(N−s)!/((N−s)−(n−k))!
módon tehetjük meg (ismétlés nélküli variáció);
(3) mivel (1) minden lehetséges esetéhez (2) minden lehetséges esete tartozhat, a lehetséges esetek száma összeszorzódik, azaz
k3=k1*k2;
(4) az 's' darab selejtet az 'n' elemű mintában "bárhol" megkaphatjuk, vagyis
k4=*k3
(ismétléses permutáció, vagy ismétlés nélküli kombináció).
A kedvező esetek számára (némi számolás után)
kΣ=*n!
adódik.
Az összes eset könnyen megkapható, mivel 'N' termékből 'n' darab mintaelemet veszünk egymás után, visszatevés nélkül (ismétlés nélküli variáció), vagyis
nΣ=N!/(N-n)! adódik.
A valószínűség klasszikus kiszámítási módja alapján
P(k)=kΣ/nΣ,
ami, ha az n! értékét "átvisszük" a tört nevezőjébe, éppen a fenti képletet adja, vagyis a P(k) valségek kétféle kiszámítási módja ugyanahhoz az értékhez vezet.
Legyen kmax=min(n,s), ekkor világos, hogy az n elemű mintában
0≤k≤kmax
selejt fordulhat elő. Tehát a valószínűségek
Egy tipikus példa hipergeometrikus eloszlásra a lottóhúzás. Ekkor P(0) annak a valsége, hogy nem volt egy találatunk sem, P(1) annak a valsége, hogy egy találatunk volt, ..., és P(5) annak a valsége, hogy ötös találatunk lett a lottón.
visszatevéses mintavétel
Legyen 'N' darab termékünk, és legyen ezek között 's' darab selejt (1≤s≤N). Vegyünk ki a termékekből egymás után 'n' darabot (1≤n<<N), és a kivett terméket minden alkalommal tegyük is vissza. Határozzuk meg annak a valségét, hogy ezek között 'k' darab selejt lesz (0≤k≤s, 0≤k≤n) (Reimann-Tóth 1985: 27-28). A megoldás:
P(k)
=
(
n
)
sk (N−s)n−k
k
Nn
A fenti formulában ismétléses variációt használtunk, azaz ha s1 és s2 két különböző selejt, és
m1, m2,
...,
m(n−2)
tetszőleges termékek, akkor pl. n=4, k=2 esetén az
(s1,s2,m1,m2)
és az
(s2,s1,m1,m2)
minták különbözőek lesznek.
A fenti formula számlálójában szereplő binomiális együttható n elem összes ismétléses permutációjának számát adja k és (n−k) azonos elem mellett. Ez a k darab selejtet és n−k darab nem selejtes terméket adó különböző minták számát adja meg, ha a mintavételek sorrendje számít, azaz pl. n=4, k=2 esetén az (s,s,n,n) és az (n,s,n,s) minták különbözőek lesznek.
Adott N, s és n mellett, továbbá kmax=min(n,s) jelöléssel az n elemű mintában
0≤k≤kmax
selejt fordulhat elő. Tehát a valószínűségek
Adjunk egy példát binomiális eloszlásra. Legyen egy akváriumban N darab hal, amelyek össze-vissza (azaz "véletlenszerűen") úszkálnak. A halak között van 's' darab aranyhal. Gondolatban válasszuk ki azokat a halakat, amelyek közel jönnek hozzánk, és addig figyeljük őket, amíg 'n' halat nem láttunk (tegyük fel, hogy s>n teljesül). Ekkor P(0) annak a valsége, hogy a megfigyelt halak közt nem volt aranyhal, P(1) annak a valsége, hogy a megfigyelt halak közt egy aranyhal volt, ..., P(n) pedig annak a valsége, hogy a megfigyelt halak közt 'n' darab aranyhal volt, azaz minden megfigyelt hal aranyhal volt. (Jegyezzük meg, hogy ha megfigyelt halakat kivennénk az akváriumból, hipergeometrikus eloszlást kapnánk.)
A binomiális eloszlás valószínűségi értékeit például az alábbi programmal írathatjuk ki:
/* binomiális eloszlás */
function hatvany(x,n) {
// csak egész n-re
if(n==0) {
return 1; // feltétel: x nem 0
}
var i=1;
var h=1;
while(i<=n) {
h=h*x;
i=i+1;
}
return h;
}
function fakt(n) {
var f=1;
var i=1;
while(i<=n) {
f=f*i;
i=i+1;
}
return f;
}
function n_alatt_k(n,k) {
// csak viszonylag kis n és k esetén :)
var a=fakt(n);
var b=fakt(k)*fakt(n-k);
return a/b;
}
function binomialis(i) {
var bn=n_alatt_k(n,i);
bn=bn*hatvany(p,i)*hatvany(q,n-i);
return bn;
}
// főprogram
writeln("Binomiális eloszlás");
var n=6;
var p=0.3, q=0.7; // q=1-p;
writeln("n="+n+", p="+p);
var i=0;
var sb="";
var sumb=0;
while(i<=n) {
sb+=binomialis(i).toFixed(2)+" ";
sumb+=binomialis(i);
i=i+1;
}
writeln();
writeln("binomiális eloszlás:\n"+sb);
writeln();
writeln("összeg: "+sumb.toFixed(2));
writeln("___________");
Ábrázoljuk egy hisztogramon a binomiális eloszlás valószínűségértékeit (n=6 paraméter mellett).
p =
1.00
0.95
0.90
0.85
0.80
0.75
0.70
0.65
0.60
0.55
0.50
0.45
0.40
0.35
0.30
0.25
0.20
0.15
0.10
0.05
0.00
0
1
2
3
4
5
6
Gyakorló feladatok
(vö. Szabó 1996: 89-90; Bognárné et al. 1971: 42-43)
(1) Válasszunk ki 10 számjegyet a {0,1,2,...,9} decimális számjegyek közül úgy, hogy megengedjük a számjegyek ismétlődését, és a számjegyek sorrendjét nem vesszük figyelembe.
(1.1) Határozza meg az elemi események halmazát!
(1.2) Ha
A ⇋ "csupa páros számot választottunk" és
B ⇋ "csupa prímszámot választottunk",
mi a jelentése az A+B eseménynek?
(1.3) Ha
B ⇋ "csupa prímszámot választottunk" és
D ⇋ "csupa 5-tel osztható számot választottunk",
mi a jelentése a B*D eseménynek?
(1.4) Ha
A ⇋ "csupa páros számot választottunk" és
C ⇋ "csupa páratlan számot választottunk",
mi a jelentése az A+C eseménynek?
(1.5) Ha
C ⇋ "csupa páratlan számot választottunk" és
D ⇋ "csupa 5-tel osztható számot választottunk",
mi a jelentése a C*D eseménynek?
(2) Egy osztályból véletlenszerűen kiválasztunk egy tanulót.
(2.1) Határozza meg az elemi események halmazát!
(2.2) Ha
A ⇋ "a kiválasztott tanuló fiú",
B ⇋ "a kiválasztott tanuló nem dohányzik" és
C ⇋ "a kiválasztott tanuló kollégista",
mi a jelentése az A*B*C eseménynek?
(2.3) Ha
A ⇋ "a kiválasztott tanuló fiú",
B ⇋ "a kiválasztott tanuló nem dohányzik" és
C ⇋ "a kiválasztott tanuló kollégista",
milyen feltételek mellett teljesül az
A*B*C=A
összefüggés?
(2.4) Ha
A ⇋ "a kiválasztott tanuló fiú" és
B ⇋ "a kiválasztott tanuló nem dohányzik",
milyen feltételek mellett teljesül az A=B
összefüggés?
(3) Ha két szabályos kockával dobunk, mennyi a valsége, hogy
(3.1) a dobott számok összege egyenlő 7-tel?
(3.2) a dobott számok összege nagyobb 9-nél?
(3.3) a dobott számok összege kisbb 5-nél?
(4) Egy 32 lapos magyar kártya csomagból véletlenszerűen kihúzunk egy lapot. Mekkora annak a valsége, hogy
(4.1) ászt húzunk?
(4.2) pirosat húzunk?
(4) Egy 32 lapos magyar kártya csomagból véletlenszerűen kihúzunk (kiosztunk) 8 lapot. Mekkora annak a valsége, hogy
(4.1) a piros ász a kihúzott lapok közt van?
(4.2) a lapok között mind a négy ász ott van?
(4.3) a lapok mind egy színűek?
(5) Az ötös lottóhúzáskor mekkora a valsége
(5.1) a kettes találatnak?
(5.2) a hármas találatnak?
(5.3) a négyes találatnak?
(5.4) az ötös találatnak?
Az (5.1) feladat egy lehetséges megoldása a következő:
Az öt lottószámot
féleképpen lehet kihúzni. Ha egy "feladott" szelvényen öt számot adtunk meg, a kérdés az, hogy elvileg hány olyan lottószelvény létezik, amelyen a megadott számokból legalább kettő szerepel (ti. ezek lesznek a számunkra "kedvező" esetek).
Egyrészt az öt számból a két kihúzott számot
féleképpen tudjuk kiválasztani; másrészt pedig ezekhez a fennmaradó 88 számból
féleképpen választhatunk tetszőleges további három számot (megengedve azt is, ha pl. mind az öt számot eltaláljuk; ha csak a kettes találatokat vizsgáljuk, 88 helyett 85-öt kell írnunk). Az általunk megadott öt számból legalább két számot tartalmazó lottószelvények száma tehát
*
darab szelvény. Ezt osztva az összes lottószelvény számával, a keresett valséget kapjuk. Kiszámítva a legalább kettes találat valségére
Pa≈0.025,
a pontosan kettes találat valségére pedig
Pb≈0.022
adódik (vagyis átlagosan kb. 40 szelvényenként várható egy nyeremény).
(6) Adja meg az ötös, a hatos és a skandináv lottóhúzáshoz tartozó valószínűségeloszlásokat!
(7) Egy családban két gyerek van. Feltéve, hogy az egyik gyerek fiú, mennyi a valsége, hogy mindkét gyerek fiú?
(8) Egy 5 piros és 5 fehér golyót tartalmazó urnából egymás után (visszatevés nélkül) kihúzunk 3 golyót. Feltéve, hogy az első két húzás eredménye ugyanaz, mennyi a valsége, hogy a harmadik húzás piros?
Valószínűségi változók
Legyen Ω = { ω1, ω2, ..., ωn } eseménytér. Ekkor az elemi események halmazán értelmezett
ξ : Ω → ℝ
függvényt valószínűségi változónak (röviden valségi változónak) nevezzük. Például az A⊆Ω eseményhez rendelt
ξAindikátorváltozó, amelyet
ξA =
{
1 ha A bekövetkezett
0 ha A nem következett be (azaz A következik be)
módon definiálunk, valószínűségi változó.
Egy ξ valségi változó leképezi az Ω eseményteret a valós számok halmazára. (Szemléletesen kifejezve a ξ valségi változó "számszerűsíti" az elemi eseményeket.) Ha ξ injektív leképezés, akkor a
Rng(ξ)⊆ℝ
értékkészlet minden elemének egyértelműen megfeleltethető egy elemi esemény. Például ha kockadobás esetében
ξ(ω) ⇋ "az ω dobásnak megfelelő szám"
akkor az {1, 2, 3, 4, 5, 6} halmaz minden eleme kölcsönösen egyértelműen megad egy elemi eseményt.
Ha viszont a ξ valségi változó nem injektív, akkor a
Rng(ξ)⊆ℝ
értékkészlet minden x∈Rng(ξ) elemének az Ω egy részhalmaza, azaz egy 'Ax' esemény feleltethető meg
Ax=ξ−1(x)⊆Ω
módon. (Vagyis az Ax eseményt azok az ω∈Ω elemi események alkotják, amelyekre ξ(ω)=x teljesül.)
Egy valószínűségi változót diszkrétnek nevezünk, ha értékkészlete véges, vagy megszámlálhatóan végtelen (azaz az általa felvett értékek sorozatba rendezhetőek).
Egy valószínűségi változót folytonosnak nevezünk, ha a változó tetszőleges valós számértéket felvehet, értékkészlete "bármilyen valós számértéket tartalmazhat"
(Wikipédia).
(A folytonos valségi változók értékkészlete előállítható egy vagy (megszámlálhatóan) sok intervallum egyesítéseként (azaz az értékkészlet ún. Borel-halmazt alkot). Másképpen megfogalmazva tetszőleges x∈ℝ esetén a
{ξ<x}={ω∈Ω | ξ(ω)<x}
halmaz eseményt alkot, vö. Bíró-Vincze 2010: 367)
Legyen ξ : Ω → ℝ valségi változó, és legyen Ax⊆Ω az az esemény, amelyre
Ax = { ω∈Ω | ξ(ω)=x }
teljesül. A továbbiakban az Ax eseményt { ξ=x } módon jelöljük. Hasonló módon definiálhatjuk a { ξ<x }, { a≤ξ<b } stb. eseményeket is.
Az ilyen módon definiált események valségét röviden P(ξ=x), P(ξ<x) stb. módon fogjuk jelölni.
Több esemény esetén az események szorzata (azaz metszete) helyett használni fogjuk a vessző operátort, például az
{ a≤ξ<b }*{ c≤ξ<d }
esemény valségét
P( a≤ξ<b, c≤ξ<d )
módon fogjuk jelölni.
Legyenek ξ : Ω → ℝ és η : Ω → ℝ ugyanazon az eseménytéren értelmezett valségi változók. A ξ és η valségi változókat függetleneknek nevezzük, ha
∀ x∈ℝ ∀ y∈ℝ (
P(ξ<x, η<y)=P(ξ<x)*P(η<y) )
teljesül.
Több valségi változó (teljes) függetlensége az egyes valségi változók páronkénti függetlenségét jelenti.
Eloszlásfüggvény
Legyen ξ : Ω → ℝ valségi változó. A ξ valségi változó eloszlásfüggvénye alatt azt az
Fξ : ℝ → [0,1]
függvényt értjük, amelyre minden x∈ℝ valós szám esetén
Fξ(x)=P(ξ<x)
teljesül.
Legyen ξ : Ω → ℝ valségi változó, Fξ(x) pedig ennek az eloszlásfüggvénye. Ekkor bármilyen a, b∈ℝ, a<b valós számok esetén
(1) P(ξ<a)=Fξ(a),
(2) P(ξ≥a)=1−Fξ(a),
(3) P(a≤ξ<b)=Fξ(b)−Fξ(a)
teljesül.
Emeljük ki, hogy tetszőleges a<b∈ℝ valós számok esetén
– a { ξ<b }
esemény valószínűségét az eloszlásfüggvény ismeretében
Fξ(b)
módon, és
– az
{ a≤ξ<b }
esemény valószínűségét az eloszlásfüggvény ismeretében
Fξ(b)−Fξ(a)
módon
kaphatjuk meg.
Legyen ξ : Ω → ℝ valségi változó,
Fξ : ℝ → [0,1]
pedig ennek az eloszlásfüggvénye. Ekkor az
Fξ(x)
valós függvényre teljesül, hogy
(a) monoton növekedő,
(b) az értelmezési tartomány minden pontjában balról folytonos,
(c) −∞-ben vett határértéke 0, és
(d) +∞-ben vett határértéke 1.
Az eloszlásfüggvényt egyes esetekben
Fξ(x)=P(ξ≤x)
módon definiálják, azaz a
P(ξ≤x) valószínűségben
megengedik az egyenlőséget is. Ekkor a függvény jobbról folytonos lesz. Az angol és a német szakirodalom az eloszlásfüggvényeket rendszerint így értelmezi. Kolmogorov nyomán például Magyarországon általában a szigorú egyenlőtlenséget használják.
(Wikipédia)
Az eloszlásfüggvény segítségével egyszerűen definiálhatjuk a folytonos valószínűségi változó fogalmát:
Egy ξ : Ω → ℝ valószínűségi változót folytonosnak nevezünk, ha az
Fξ : ℝ → [0,1]
eloszlásfüggvénye folytonos (vö. Obádovics 1997: 66).
A valószínűségi változók jellemzésére meghatározott jellemzőket fogunk használni, például
– a valószínűségi változó várható értéke az az érték, amely körül feltételezésünk szerint nagy számú kísérletet elvégezve a valségi változó értéke ingadozni fog;
– a valószínűségi változó szórása pedig az az érték, amely körül feltételezésünk szerint nagy számú kísérletet elvégezve a valségi változó értékének a várható értéktől való eltérése (abszolút értékben) ingadozni fog.
Ha a ξ : Ω → { x1, x2, ..., xk, ... } valószínűségi változó diszkrét, akkor a
{pi=P(ξ=xi) | i=1,2,...}
számsorozat adja a ξ valségi változó eloszlását, amelynek segítségével definiálhatjuk a ξ változó jellemzőit (pl. várható értékét, szórásnégyzetét stb.). Egy diszkrét valségi változó eloszlása például hisztogram segítségével ábrázolható (pl. úgy, hogy a valségi változó lehetséges értékeit felvesszük az 'x' tengelyen, és az egyes értékek felett az értékek valószínűségeivel azonos (vagy arányos) magasságú téglalapokat rajzolunk).
Ha a ξ : Ω → ℝ valószínűségi változó
Fξ : ℝ → [0,1]
eloszlásfüggvénye folytonos, és (véges számú hely kivételével) differenciálható, akkor az
f(x)=F'(x)
deriváltfüggvényt a ξ valségi változó sűrűségfüggvényének nevezzük.
A sűrűségfüggvény segítségével definiálhatjuk egy ξ folytonos valségi változó meghatározott jellemzőit (például várható értékét, szórásnégyzetét stb.). A folytonos valségi változókat, ha létezik a sűrűségfüggvényük, rendszerint nem az eloszlásfüggvényükkel, hanem a sűrűségfüggvényükkel definiáljuk.
Diszkrét valószínűségi változók
eloszlás, eloszlásfüggvény
Legyen ξ : Ω → { x1, x2, ..., xk, ... } diszkrét valségi változó. A ξ diszkrét valségi változó eloszlása alatt a
{ p1=P(ξ=x1), p2=P(ξ=x2), ..., pk=P(ξ=xk), ... }
számsorozatot értjük. Mivel az ωi={ ξ=xi } események diszjunktak, és
Σi ωi=Ω
teljesül, az eloszlásértékek összege 1, azaz
Σi pi=p1+p2+...+pk+...=1
teljesül.
Például ha három kockával dobunk, akkor az eseménytér
Ω={(i,j,k) | 1≤i,j,k≤6}.
Ezen az eseménytéren definiálhatjuk a
ξ : Ω→{3,4,...,18}
diszkrét valségi változót
ξ(i,j,k)=i+j+k
módon. Az elemi események száma, azaz összes lehetséges eset n=6*6*6=216.
A definíció alapján például
P(ξ=3)=1/n,
P(ξ=4)=3/n (ugyanis az (1,1,2), (1,2,1) és (2,1,1) elemi események adják a kedvező eseteket),
stb.
Ábrázoljuk a ξ valségi változó eloszlásának a hisztogramját. A diagram vízszintes tengelyén a valségi változó értékkészletének az elemeit, a függőleges tengelyen pedig az egyes értékek gyakoriságát ábrázoljuk. (Jegyezzük meg, hogy ha a függőleges tengelyen 1-re normáljuk a gyakoriságértékeket, azaz a ξ valségi változó lehetséges értékeinek valószínűségeit ábrázoljuk, akkor a ξ valségi változó sűrűségfüggvényét kapjuk. Ebben az esetben a diagram területe 1 lesz.)
Egy diszkrét valségi változó eloszlásfüggvényének szemléltetésére tekintsük például a kockadobást. Legyen a ξ valségi változó értéke a kockadobással kapott érték. Világos, hogy
ξ : Ω → { 1, 2, 3, 4, 5, 6 }
diszkrét valségi változó, amelynek eloszlása
{ p1=1/6, p2=1/6, ..., p6=1/6 },
eloszlásfüggvénye és grafikonja pedig a következő:
x
Fξ(x)
x≤1
P(ξ<x)=0
1<x≤2
P(ξ<x)=1/6
2<x≤3
P(ξ<x)=2/6
3<x≤4
P(ξ<x)=3/6
4<x≤5
P(ξ<x)=4/6
5<x≤6
P(ξ<x)=5/6
6<x
P(ξ<x)=1
A táblázatból látszik, hogy a ξ diszkrét valségi változó eloszlásfüggvénye lépcsős függvény, amelynek a ξ valségi változó értékei mellett nem megszüntethető szakadása van.
Az eloszlásfüggvény szakadási pontjaiban a függvény ugrásának nagysága megegyezik a ξ valószínűségi változó eloszlásának értékével az adott pontban, azaz
P(ξ=xi)=F(xi+Δx)−F(xi) (0<Δx≪1, x1=1, x2=2, ..., x6=6),
ami megegyezik annak a valségével, hogy xi értéket dobunk.
Annak a valsége pedig, hogy 3-nál kisebbet dobunk, az eloszlásfüggvény ismeretében
P(ξ<3)=Fξ(3)=2/6
módon számítható ki.
A fentieket általánosan is megfogalmazhatjuk.
Legyen
ξ : Ω → { x1, x2, ..., xk, ... }
diszkrét valségi változó, amelynek eloszlása
{ p1, p2, ..., pk, ... }, ahol
pi=P(ξ=xi) (i∈ℕ).
Mivel a { ξ=x | x∈Rng(ξ) } események teljes eseményrendszert alkotnak, a ξ változó eloszlásfüggvényére
Fξ(x) =
Σ
xi<x
P(ξ=xi) =
Σ
xi<x
pi
teljesül.
Vegyük észre, hogy az eloszlásfüggvény értékét az x∈ℝ pontban úgy kapjuk meg, hogy az összes olyan
pi=P(ξ=xi)
eloszlásértéket összegezzük, amelyre
xi<x
teljesül.
Például a ξA indikátorváltozó eloszlása az
{x1=0,
x2=1}
függvényértékek mellett
{p1=1−P(A),
p2=P(A)},
tehát az FξA(x) eloszlásfüggvény értéke például az x=1 pontban
FξA(1)=
P(ξA<1)=
p1=
1−P(A)
mivel egyedül az x1 értékre teljesül az x1<1 feltétel.
várható érték
Legyen ξ : Ω → { x1, x2, ..., xk, ... } diszkrét valségi változó, amelynek eloszlása
{ p1, p2, ..., pk, ... }.
Ekkor a ξ változó várható értéke
M(ξ) =
∞
Σ
i=1
xi*pi
Megszámlálhatóan végtelen értékkészlet esetén csak akkor beszélhetünk a ξ valségi változó várható értékéről, ha a fenti összeg létezik (ti. a részletösszegekből álló sorozat konvergens).
Egy diszkrét valségi változó várható értékének szemléltetésére tekintsük ismét a kockadobást. Mivel ekkor a ξ valségi változó értéke a kockadobással kapott érték, a
ξ : Ω → { 1, 2, 3, 4, 5, 6 }
diszkrét valségi változó eloszlása
{ p1=1/6, p2=1/6, ..., p6=1/6 }.
A várható érték ennek alapján
M(ξ) = (1/6 + 2/6 + 3/6 + 4/6 + 5/6 + 6/6) = 3.5
módon számítható ki. (Hipotézisünk az, hogy elegendően sok kockadobást elvégezve a ξ valségi változó értékei az így kiszámolt érték körül ingadoznak.)
Egy másik példaként számítsuk ki a ξAindikátorváltozó várható értékét. Ha p=P(A), akkor definíció szerint
M(ξA) = 1*p + 0*(1−p) = p
vagyis a ξA indikátorváltozó várható értéke éppen az 'A' esemény valószínűsége.
Legyenek ξ : Ω → { x1, x2, ..., xk, ... } és
η : Ω → { x1, x2, ..., xk, ... }
diszkrét valségi változók, amelyek várható értéke M(ξ) és M(η). Ekkor teljesülnek az alábbiak:
(1) Ha ξ=c (azaz ξ konstans, vagyis xi=c minden i∈ℕ esetén), akkor M(ξ)=c teljesül.
(2) Ha c∈ℝ tetszőleges valós szám, akkor
M(c*ξ)=c*M(ξ)
teljesül.
Például modellezzük az 'n' elemű visszatevéses mintavételt egy
ξ=ξA,1+ξA,1+...+ξA,n
valségi változóval, ahol a ξA,i valségi változók az 'A' esemény (a selejtes termék választásának) indikátorváltozói az i-dik termék választása esetén (i=1,2,...,n). Ekkor
M(ξA,i)=p (i=1,2,...,n)
és a várható érték additivitása miatt
M(ξ)=n*p
teljesül.
szórás, szórásnégyzet
Legyen ξ : Ω → { x1, x2, ..., xk, ... } diszkrét valségi változó, amelynek várható értéke m=M(ξ).
Ekkor a ξ valségi változó szórásnégyzete a
(ξ−m)2
valségi változó várható értéke, azaz
D2(ξ) = M((ξ−m)2).
A várható érték definíciója alapján a szórásnégyzet
D2(ξ) =
∞
Σ
i=1
(xi−m)2*pi
módon számítható ki.
Megszámlálhatóan végtelen értékkészlet esetén csak akkor beszélhetünk a ξ valségi változó szórásnégyzetéről, ha a fenti összeg létezik (azaz a részletösszegekből álló sorozat konvergens).
Egy diszkrét valségi változó szórásnégyzetének szemléltetésére tekintsük ismét a kockadobást. Mivel ekkor a ξ valségi változó értéke a kockadobással kapott érték, a
ξ : Ω → { 1, 2, 3, 4, 5, 6 }
diszkrét valségi változó eloszlása
{ p1=1/6, p2=1/6, ..., p6=1/6 }.
A szórásnégyzet a várható érték ismeretében (M(ξ)=m=3.5)
D2(ξ) =
(1−3.5)2*1/6 +
(2−3.5)2*1/6 +
(3−3.5)2*1/6 +
(4−3.5)2*1/6 +
(5−3.5)2*1/6 +
(6−3.5)2*1/6
≈ 2.92
módon számítható ki. (Hipotézisünk az, hogy elegendően sok kockadobást elvégezve a ξ valségi változó értékeinek a várható értéktől való (abszolút értékben vett) eltérései a
D(ξ) ≈ 1.71
érték körül ingadoznak.)
Kockadobás esetén a ξ valségi változó várható értékét és szórásnégyzetét például az alábbi JavaScript programmal számíthatjuk ki:
/* kockadobás várható értéke és szórásnégyzete */
var sum=0;
for(var i=1;i<=6;i++) {
sum+=i*(1/6);
}
var m=sum;
writeln("a kockadobás várható értéke: "+m);
writeln();
sum=0;
for(var i=1;i<=6;i++) {
sum+=i*i*(1/6);
}
var m2=sum;
writeln("a kockadobás négyzetének várható értéke: "+m2);
writeln();
sum=0;
for(var i=1;i<=6;i++) {
sum+=(m-i)*(m-i)*(1/6);
}
var d2=sum;
writeln("a kockadobás szórásnégyzete: "+d2);
writeln();
writeln("-----");
Egy másik példaként számítsuk ki a ξAindikátorváltozó szórásnégyzetét. Korábban láttuk, hogy p=P(A) jelölés mellett az indikátorváltozó várható értékére m=M(ξA)=p teljesül, ezért a szórásnégyzet
D2(ξA) = (1−p)2*p + (0−p)2*(1−p) = p*(1−p) = p*q
módon számítható ki (q=1−p jelöléssel).
Jegyezzük meg, hogy a szórásnégyzet p=q=0.5 esetén maximális (ekkor D2(ξA)=1/4).
Legyen ξ : Ω → { x1, x2, ..., xk, ... } diszkrét valségi változó, amelynek várható értéke m=M(ξ). Ekkor teljesülnek az alábbiak:
(1) D2(ξ) = M(ξ2)−M2(ξ)
= M(ξ2)−m2.
(1.1) Mivel D2(ξ)≥0, ezért (1)-ből
M(ξ2) ≥ M2(ξ)
következik.
(2) Ha ξ=c (azaz ξ konstans), akkor D2(ξ) = 0 teljesül.
(3) Ha c∈ℝ tetszőleges szám, akkor, akkor
D2(c*ξ) = c2*D2(ξ) teljesül.
Például (1) alapján a kockadobás szórásnégyzete M(ξ)=m=3.5 és
M(ξ2) = (1*1)/6 + (2*2)/6 + (3*3)/6 + (4*4)/6 + (5*5)/6 + (6*6)/6 ≈ 15.17 miatt
D2(ξ) ≈
15.17 − 3.52 =
15.17 − 12.25 ≈ 2.92
módon számítható ki.
Legyenek ξ : Ω → { x1, x2, ..., xk, ... } és
η : Ω → { x1, x2, ..., xk, ... }
diszkrét és független valségi változók, amelyek szórásnégyzete D2(ξ) és D2(η). Ekkor
D2(ξ+η)=D2(ξ)+D2(η)
teljesül.
Kockadobások modellezése (alapértelmezés: 100 dobásból álló sorozatok végrehajtása 100-szor)
x tengely: kockadobások értéke: [1...6]
y tengely: kockadobások relatív gyakorisága: [0,1]
kék és piros vonások: egy dobás esetén a várható értéktől (3.5) való várható eltérés (szórás vagy "hiba") "elméleti" értéke (±1.71)
szürke pontsorok: az egyes dobások relatív gyakoriságai az egyes sorozatokban
piros pontok (zöld színnel összekötve): az egyes sorozatok empirikus várható értékeinek gyakorisága (1-re normálva)
a sorozatok várható értékének átlaga és hibája 100 dobás esetén:
Megjegyzés: a sorozatok átlagos várható értékének a hibája csak 1 dobásból álló sorozatok esetén közelíti meg a szórás "elméleti" értékét. Minél több dobásból áll egy sorozat, a várható érték hibájának az értéke egyre kisebb lesz.
kockadobások száma sorozatonként:
szimuláció újrakezdése:
Egy ξ valségi változó értékét nem tudjuk előre pontosan megmondani, mivel az a "véletlentől függ". Azonban elméletileg
– egy 'n' elemű mintavétel során ξ értéke az M(ξ) várható érték körül ingadozik;
– a ξ valségi változó értékének az M(ξ) várható értéktől való eltérése, azaz az
|ξ−M(ξ)|
érték (szemléletesen kifejezve a mintavétel során megfigyelt értékek "hibája") a D(ξ) szórás körül ingadozik.
A gyakorlatban (például egy 'n' elemből álló méréssorozat kiértékelésekor) általában feltételezzük, hogy a mintavételek ("mérések") során kapott ξi értékekre elegendően "nagy valószínűséggel"
ξi∈(M(ξ)−D(ξ),M(ξ)+D(ξ))
teljesül (i=1,2,...,n), vagy másképpen megfogalmazva
ξi=ξ±Δ
ahol ξ≈M(ξ) a mért eredmények középértéke (átlaga), és Δ≈D(ξ) a mérés hibája.
Egy 'n' elemű mintavétel esetén az M(ξ) várható értéket a mintavétel során megfigyelt ξ1, ξ2, ..., ξn értékek ξ=(ξ1+ξ2+...+ξn)/n empirikus középértékével,
a D(ξ) szórást ("hibát") pedig az
S2(ξ)=[(ξ1−ξ)2+(ξ2−ξ)2+...+(ξn−ξ)2]/n
módon kiszámítható empirikus szórásnégyzet négyzetgyökével közelíthetjük.
kovariancia, korreláció
Legyenek
ξ : Ω → {x1, x2, ..., xn}
és
η : Ω → {y1, y2, ..., ym}
diszkrét, véges értékkészletű valségi változók, amelyek
várható értéke M(ξ) és M(η), továbbá
szórásnégyzete D2(ξ) és D2(η), eloszlásuk pedig
pi=P(ξ=xi) (1≤i≤n, i∈ℕ)
és
qj=P(η=yi) (1≤j≤n, j∈ℕ).
Legyenek továbbá a
pij=P(ξ=xi, η=yj) (1≤i≤n, 1≤j≤m, i,j∈ℕ)
értékek az
{ω∈Ω | ξ(ω)=xi}*{ω∈Ω | η(ω)=yj}
események előfordulásának valószínűségei (1≤i≤n, 1≤j≤m, i,j∈ℕ).
Vezessük be a következő jelöléseket:
(1) A ξ és η valségi változók peremeloszlásának nevezzük a
wξ :
{x1, x2, ..., xn}
→ {pi | 1≤i≤n, i∈ℕ}
wξ(xi)=pi
(1≤i≤n, i∈ℕ)
és a
wη :
{y1, y2, ..., ym}
→ {qj | 1≤j≤m, i∈ℕ}
wη(yj)=qj
(1≤j≤m, j∈ℕ)
függvényeket.
(2) A ξ és η valségi változók együttes eloszlásának nevezzük a
wξη :
{x1, x2, ..., xn}Χ{y1, y2, ..., ym}
→ {pij | 1≤i≤n, 1≤j≤m, i,j∈ℕ}
wξη(xi,yj)=pij
(1≤i≤n, 1≤j≤m, i,j∈ℕ)
függvényt.
ξ és η valségi változók wξηegyüttes eloszlásának ismeretében a peremeloszlások meghatározhatók:
wξ(xi) =
Σ(j=1;j≤m;j→j+1)wξη(xi,yj)
wη(yj) =
Σ(i=1;i≤n;i→i+1)wξη(xi,yj)
A ξ és η valségi változók sztochasztikus kapcsolatának jellemzésére vezessük be
a ξ és η valségi változók kovarianciáját és korrelációs együtthatóját.
Ha a ξ és η valségi változók függetlenek, akkor
Cov(ξ,η) = 0 és
R(ξ,η) = 0
teljesül. Azonban
a kovariancia és a korreláció zérus értéke a függetlenség szükséges, de nem elégséges feltétele (azaz ha a kovariancia és a korreláció zérus, abból még nem feltétlenül következik, hogy a valségi változók függetlenek);
de ha a kovariancia és a korreláció értéke nem zérus, akkor a ξ és η valségi változók biztosan nem függetlenek.
Ha ξ és η valségi változók függetlenek, akkor az együttes eloszlásra
wξη(xi,yj) =
wξ(xi)*wη(yj)
(1≤i≤n, 1≤j≤m)
teljesül.
Ha a ξ és η valségi változók korrelációs együtthatójára
R(ξ,η)=±1
teljesül, akkor a valószínűségi változók között lineáris függvénykapcsolat van, azaz
ξ=a*η+b (a, b∈ℝ)
teljesül. (Mj.: a függetlenség "ellentéte", ha két változó között meghatározott függvénykapcsolat van.)
Ha a korrelációs együttható 0, akkor a valségi változókat korrelálatlanoknak nevezzük.
Ha a korrelációs együttható abszolút értéke közel van 1-hez, akkor a valségi változókat erősen korreláltaknak nevezzük.
Tekintsük az alábbi példát (Obádovics 1997: 63-64)
ξ ↓ / η →
y1=4
y2=10
Σ(sorok)
x1=2
wξη(x1,y1)=0
wξη(x1,y2)=0.5
wξ(x1)=0.5
x2=6
wξη(x2,y1)=0.5
wξη(x2,y2)=0
wξ(x2)=0.5
Σ(oszlopok)
wη(y1)=0.5
wη(y2)=0.5
A ξ és η valségi változók várható értéke:
M(ξ)=2*0.5+6*0.5=4
M(η)=4*0.5+10*0.5=7
A ξ és η valségi változók szórásnégyzete:
D2(ξ)=(2-4)2*0.5+(6-4)2*0.5=4
⇒ D(ξ)=2
D2(η)=(4-7)2*0.5+(10-7)2*0.5=9
⇒ D(η)=3
A ξ és η valségi változók korrelációs együtthatója:
R(ξ,η)=(-6)/(2*3)=-1
Mivel a ξ és η valségi változók korrelációs együtthatója −1, ezért a valségi változók közt lineáris kapcsolat áll fenn.
Ennek alakja:
η=1.5*ξ+1
(Ellenőrzés: 1.5*2+1=3+1=4 és 1.5*6+1=9+1=10 teljesül.)
Valószínűségeloszlások
Binomiális eloszlás
A korábban említett példa visszatevéses mintavételre a következő volt:
legyen N darab termékünk, és legyen ezek között 's' darab selejt. Vegyünk ki a termékekből egymás után 'n' darabot, és a kivett terméket minden alkalommal tegyük is vissza. Határozzuk meg annak a valségét, hogy ezek között k≤s darab selejt lesz.
Adjuk meg a
ξ : Ω → {0, 1, ..., n}⊆ℕ
valségi változóval a teljes (n elemű) mintában levő selejtek darabszámát (általánosan fogalmazva a mintavétel során vizsgált, "kedvező" esetek gyakoriságát). Jelöljük egy mintavétel során egy selejt kiválasztásának valségét (a "selejtarányt")
p=s/N
módon, és egy nem selejtes termék kiválasztásának valségét
q=1−p
módon. Ekkor az ún. binomiális eloszláshoz jutunk:
P(ξ=k)
=
(
n
)
pk (1−p)n−k
k
=
(
n
)
pk qn−k
k
Általánosítsuk a binomiális eloszláshoz vezető feladatot:
– klasszikus valószínűségi mezőt tételezünk fel;
– egy 'n' elemű mintavétel során két kimenetel, A és B=A lehetséges,
pA=p és
pB=1−p=q
valséggel;
– egy mintavétel nem befolyásolja a többi mintavételt: a mintavételek egymástól függetlenek és "visszatevéses" mintavétel történik (megjegyzés: ha pl. tőlünk független tömegjelenségeket figyelünk meg, ezt rendszerint feltételezzük);
– 'n' darab mintát veszünk, és keressük az A kimenetel (a "kedvező esetek") gyakoriságát (ξ) és az A esemény k-szor történő előfordulásának P(ξ=k) valségét, azaz a ξ diszkrét valségi változó eloszlását (k=0,1,...,n).
Legyen
ξ : Ω → {0, 1, ..., n}⊆ℕ
binomiális eloszlású valségi változó, amely az 'n' elemű mintavétel során a "kedvező" esetek gyakoriságát adja meg. Ekkor teljesülnek az alábbiak:
(1) A { ξ=k } események teljes eseményrendszert alkotnak (0≤k≤n).
(2) M(ξ) = n*p
teljesül, vagyis a binomiális eloszlású ξ valségi változó esetén a "kedvező" eseteknek, azaz a 'p' valségű 'A' esemény bekövetkezéseinek ξ gyakorisága 'n' kísérlet során n*p körül,
a "kedvező" esetek
η=ξ/n
relatív gyakorisága pedig a megfigyelt 'A' esemény
pA=p
valószínűsége körül ingadozik.
A fenti összefüggés abból is következik, hogy az egyes mintavételeket függetlennek tekintjük, és ha
ξi=ξA,i
jelöli az 'A' esemény indikátorváltozóját az i-dik mintavétel során, akkor az 'A' bekövetkezéseinek gyakoriságát megadó ξ valségi változó
ξ=ξ1+ξ2+...+ξn
módon állítható elő, ahol
M(ξi)=M(ξA,i)=p,
(i=1,2,...,n) teljesül.
(3) D2(ξ) = n*p*q teljesül.
A ξ valségi változó az 'A' esemény bekövetkezésének gyakoriságát adja meg 'n' elemű mintavétel esetén. Mivel egy mintavétel esetén az 'A' esemény bekövetkezését a ξAindikátorváltozó adja meg, 'n' elemű mintavétel esetén a ξA indikátorváltozó empirikus középértékének várható értékét és szórásnégyzetét
M(ξA)=M[(ξ1+ξ2+...+ξn)/n]=M(ξ/n)=M(ξ)/n=n*p/n=p és
D2(ξA)=D2[(ξ1+ξ2+...+ξn)/n]=D2(ξ)/n2=(n*p*q)/n2=p*q/n
módon számíthatjuk ki, ξAempirikus szórásnégyzetének várható értékét pedig
M(S2(ξA))=
M{[(ξ1−ξA)2+(ξ2−ξA)2+... +(ξn−ξA)2]/n}= ... =
(n−1)*p*q/n
módon (elegendően nagy 'n' esetén
M(S2(ξA))≈ p*q).
Jegyezzük meg, hogy a korrigált empirikus szórásnégyzet várható értékére pontosan
M(Sk2(ξA))= p*q
adódik (bármilyen 'n' esetén).
A szórásnégyzet értéke abból következik, hogy
(1) tetszőleges i=1,2,...,n esetén M(ξi)=p és
D2(ξi)=p*q, valamint
D2(ξi)=
M(ξi2)−M2(ξi)=
M(ξi2)−p2 és
(2) M(ξA)=p és
D2(ξA)=p*q/n, valamint
D2(ξA)=
M(ξA2)−M2(ξA)=
M(ξA2)−p2
teljesül.
Tehát egyrészt
M(ξi2)=p*q+p2,
másrészt
M(ξA2)=p*q/n+p2
teljesül. Emellett
(3) tetszőleges i=1,2,...,n esetén M(ξi*ξA)=
M[ξi*(ξ1+ξ2+ ... +ξn)/n]=
M[(ξi*ξ1+ξi*ξ2+ ... +ξi*ξi+ ... +ξi*ξn)/n]=
[M(ξi)*M(ξ1)+M(ξi)*M(ξ2)+ ... +M(ξi2)+ ... +M(ξi)*M(ξn)]/n=
[(n−1)*p2+p*q+p2]/n=
(n*p2+p*q)/n=
p2+p*q/n teljesül. Vagyis
M(ξi*ξA)=p2+p*q/n
teljesül. Ezeket behelyettesítve tetszőleges i-re (i=1,2,...,n) esetén
M[(ξi−ξA)2]=
M(ξi2−2*ξi*ξA+ξA2)=
M(ξi2)−2*M(ξi*ξA)+M(ξA2)=
p*q+p2−2*[p2+p*q/n]+p*q/n+p2=
p*q−p*q/n=
(n−1)*p*q/n
teljesül.
(4) D2(ξ) ≤ n/4 teljesül.
(Mivel a másodfokú
p*q=p*(1−p)=−p2+p
függvény akkor a legnagyobb, ha p=0.5 és q=(1−p)=0.5, ezért
D2(ξ)≤n*0.52=n/4
teljesül.)
A Weldon-féle kockadobási kísérlet a következő (Feller 1978: 150-151):
Egy kísérlet során 12-szer dobunk egy kockával (vagyis n=12 elemű mintavétel történik), és vizsgáljuk, hányszor dobtunk ötöst vagy hatost. Vagyis az eseménytér
Ω=Ω1xΩ2x...xΩ12,
ahol
Ωi={ωi1, ωi2, ..., ωi6}
az i-dik dobás eredménye (i=1,2,...,12). Világos, hogy az elemi események
(ω1,j1,ω2,j2,...,ω12,j12)
alakúak (ahol ωi,j azt jelenti, hogy az i-dik dobáskor j-t dobtunk).
Vezessük be a
ξ:Ω→{0,1,...,12}
valségi változót, amely azt adja meg, hogy egy 12 dobásos kísérlet (mintavétel) során hányszor fordultak elő a "jó esetek" (A), azaz hányszor dobtunk ötöst vagy hatost.
Az 'A' esemény elméleti valsége egy dobáskor
p=1/3,
és egy szabályos ("nem cinkelt") kockával dobva a ξ valségi változóra binomiális eloszlást tételezhetünk fel.
A ξ valségi változó kifejezhető az 'A' esemény i-dik dobásra vonatkozó ξA,i (i=1,2,...,12) egymástól független indikátorváltozóinak segítségével
ξ=ξA,1+ξA,2+...+ξA,12
módon.
Az eredeti Weldon-féle kísérletet ("kézzel") 26306-szor hajtották végre. Modellezzük most ezt a kísérletet számítógéppel és adjuk meg egy táblázatban az 'A' esemény előfordulásának megfigyelt gyakoriságait, valamint a binomiális eloszlásból következő "elméleti" valószínűségeket (azaz a binomiális eloszlású ξ valségi változó k=0, k=1, ..., k=12 értékeinek valségét n=12, p=1/3, q=2/3 paraméterekkel).
A táblázat magyarázata:
– 'k' értéke azt adja meg, hogy egy n=12 dobásos kísérletben hányszor fordult elő a p=1/3 valségű 'A' esemény (azaz esetünkben az 5-ös vagy 6-os dobásnak megfelelő "jó esetek");
– az elméleti valószínűség (B) oszlopban a binomiális eloszlás P(ξ=k) valószínűségei szerepelnek n=12 és p=1/3, q=2/3 paraméterek mellett;
– a relatív gyakoriság (R) oszlopban az 'A' esemény 'k'-szori előfordulásának "megfigyelt"
relatív gyakorisága
szerepel (26306 kísérlet mellett);
– az utolsó, |B−R| oszlopban pedig az "elméleti" valószínűségek és a kapott relatív gyakoriságok abszolút értékben vett eltérése szerepel.
A táblázatban
rózsaszínnel
kiemeltük azt a sort, amely egy kísérlet során az elméletileg legvalószínűbb k=4 értékhez tartozik (ekkor P(ξ=4)≈0.2384). A k=4 gyakorisághoz tartozó sor alatt és felett világosabb színnel kiemeltük azokat a sorokat
(k=3 és k=5, ill.
k=2 és k=6),
amelyek a kísérletek eredményeinek "szórása" miatt még várhatóan viszonylag nagyobb gyakorisággal elő fognak fordulni
(n=12 és p=1/3 mellett a "jó" esetek száma M(ξ)=n*p=4 körül ingadozik D2(ξ)=n*p*q≈2.667 ⇒ D(ξ)≈1,633 átlagos hibával).
Az 'A' esemény bekövetkezésének "elméletileg" legvalószínűbb gyakoriságát egy kísérlet során a ξ valségi változó M(ξ)=4 várható értéke adja meg.
Az ehhez az értékhez tartozó relatív gyakoriságot egy kísérlet során M(ξ)/n=4/12=1/3 módon számíthatjuk ki, amely az indikátorváltozók tulajdonságaiból következő
P(A)=M(ξA,i) (i=1,2,...,12) miatt, továbbá az egyes dobásokhoz tartozó ξA,i indikátorváltozók függetlenségéből következő
M(ξ)=M(ξA,1)+M(ξA,2)+...+M(ξA,12)=n*P(A)
miatt megegyezik az 'A' esemény P(A)=1/3 valószínűségével.
Ha ξi-vel jelöljük azokat a valségi változókat, amelyek egy adott n=12 dobásos kísérletben megadják a "jó esetek", azaz az 'A' esemény gyakoriságát (ahol ξi∈{0,1,...,12}, i=1,2,...,26306), akkor az egyes kísérletek során megfigyelt ("empirikus") gyakoriságok átlagát a teljes Weldon-féle kockadobási kísérletben a ξ=(ξ1+ξ2+...+ξ26306)/26306 empirikus várható érték kiszámításával kaphatjuk meg. Ennek megfelelően az 'A' esemény (átlagos) empirikus relatív gyakoriságát egy kísérlet során
ξ/n
módon számíthatjuk ki (ahol n=12). Az egyes kísérletek során kapott ξi gyakorisági értékeket a fenti tört számlálójában csoportosíthatjuk a gyakoriságok aktuális értéke szerint. Ha ηk jelöli azoknak a ξi gyakoriságoknak a számát, amelyekre ξi=k teljesül (k=0,1,...,n), akkor a fenti összefüggés ξ=(η0*0+η1*1+η2*2+...+ηn*n)/26306
módon is felírható (ahol n=12). A táblázat harmadik oszlopában az R=ηk/26306 értékeket ábrázoltuk (k=0,1,...,n).
Jegyezzük meg végül, hogy a ξ valségi változó megfigyelésével kapott átlagos (empirikus) gyakorisági értéknek a megfigyelések során tapasztalt (átlagos) hibáját az
S2(ξ)=((ξ1−ξ)2+(ξ2−ξ)2+...+(ξ26306−ξ)2)/26306 empirikus szórásnégyzet kiszámításával kaphatnánk meg (ez azonban a táblázatban nem szerepel).
Hipergeometrikus eloszlás
A korábban említett példa visszatevés nélküli mintavételre a következő volt:
legyen N darab termékünk, és legyen ezek között s darab selejt. Vegyünk a termékekből egy n elemű mintát (egyszerre vagy egymás után, de visszatevés nélkül), és határozzuk meg annak a valségét, hogy ezek között k≤s darab selejt lesz.
Adjuk meg a
ξ : Ω → {0, 1, ..., n}⊆ℕ
valségi változóval a teljes (n elemű) mintában levő selejtek darabszámát. Tételezzük fel továbbá, hogy N (azonos valséggel kiválasztható) termékünk van, és ebben s darab selejt található (1≤s≤N, 1≤n≤N).
Ekkor az ún. hipergeometrikus eloszláshoz jutunk:
P(ξ=k)
=
(
s
)
(
N−s
)
k
n−k
(
N
)
n
Általánosítva a hipergeometrikus eloszláshoz vezető feladatot:
– klasszikus valószínűségi mezőt tételezünk fel;
– egy n elemű mintavétel során két kimenetel, A és B lehetséges;
– N termék között s darab A típusú és (N−s) darab B típusú termék található, így az A és B termék kiválasztásának valsége az első mintavétel során
pA=p=s/N és
qB=1−p=q;
– a mintavételek nem függetlenek, minden mintavétel befolyásolja a további mintavételeket, mert egy termék kiválasztásával a még választható termékek száma eggyel csökken ("visszatevés nélküli" mintavétel történik);
– n darab mintát veszünk, és keressük az A kimenetel gyakoriságát (ξ), valamint az A esemény k-szor történő előfordulásának P(ξ=k) valségét (k=0,1,...,n).
Legyen
ξ : Ω → {0, 1, ..., n}⊆ℕ
hipergeometrikus eloszlású valségi változó. Ekkor
(1) a { ξ=k } események teljes eseményrendszert alkotnak (0≤k≤n);
(2) M(ξ) = n*p
(a hipergeometrikus eloszlás várható értéke megegyezik a binomiális eloszlás várható értékével);
(3) D2(ξ) = n*p*q*[1 − (n−1)/(N−1)];
(4) ha n<<N, akkor a hipergeometrikus eloszlás szórásnégyzete közelítőleg megegyezik a binomiális eloszlás szórásnégyzetével (ebben az esetben a hipergeometrikus eloszlást közelíthetjük a binomiális eloszlás segítségével).
Poisson-eloszlás
Legyen
ξ : Ω → {0, 1, 2, ..., ∞}=ℕ
valségi változó, λ>0 pozitív valós szám.
Ekkor az ún. λ paraméterű Poisson eloszlást a következőképpen definiáljuk:
P(ξ=k)
=
λk
e−λ
k!
A Poisson-eloszlás "a diszkrét valószínűségeloszlások közül [...] a legfontosabb". Az eloszlást "a kis valószínűségű, vagyis ritka események eloszlástörvényének is nevezik" (Reimann-Tóth 1985: 85).
Legyen
ξ : Ω → {0, 1, 2, ..., ∞}=ℕ
Poisson-eloszlású valségi változó λ>0 paraméterrel. Ekkor
(1) a { ξ=k } események teljes eseményrendszert alkotnak (k∈ℕ);
(2) M(ξ) = λ
(mivel a Poisson-eloszlás várható értéke megegyezik a λ paraméter értékével, a várható értékre vonatkozó becsléssel a λ paraméter statisztikailag megbecsülhető);
(3) D2(ξ) = λ;
(4) ha n→∞ p→0 és n*p=c∈ℝ állandó, akkor
lim
n→∞
(
n
)
pk qn−k =
(np)k
e−np
k
k!
teljesül. (Nagy minták, azaz n≫0 esetén a binomiális eloszlást közelíthetjük λ=n*p paraméterű Poisson-eloszlás segítségével.)
Egyenletes eloszlás (diszkrét)
Legyen
ξ : Ω → {x1, x2, ..., xn}⊆ℝ
diszkrét valségi változó, n≥1 természetes szám.
Ekkor az ún. egyenletes eloszlást a következőképpen definiáljuk:
P(ξ=xk)
=
1
n
Általánosítva az egyenletes eloszláshoz vezető feladatot:
– az eseménytér (az elemi események száma) véges;
– minden elemi esemény azonosan valószínű (azaz alkalmazható a valószínűség klasszikus kiszámítási módja).
Legyen
ξ : Ω → {x1, x2, ..., xn}⊆ℝ
egyenletes eloszlású valségi változó. Ekkor
(1) a { ξ=xk } események teljes eseményrendszert alkotnak (1≤k≤n);
(2) a ξ egyenletes eloszlású valségi változó várható értéke
M(ξ) =
1
n
Σ
i=1
xi
n
(3) a ξ egyenletes eloszlású valségi változó szórásnégyzete
D2(ξ) =
1
n
Σ
i=1
xi2
−m2
n
ahol m=M(ξ) a ξ valségi változó várható értékét jelöli.
Normális eloszlás
Legyen
ξ : Ω → ℝ
folytonos valségi változó,
m∈ℝ tetszőleges valós szám,
σ∈ℝ, σ>0 pozitív valós szám.
Ekkor az ún. normális eloszlást a következő sűrűségfüggvénnyel definiálhatjuk:
Az 'm' paramétert a normális eloszlás várható értéke, és a 'σ' paraméter a normális eloszlás szórása.
Ha m=0 és σ=1, akkor ún. standard normális eloszlásról szokás beszélni. A standard normális eloszlás sűrűségfüggvényét φ(x), eloszlásfüggvényét pedig Φ(x) módon jelöljük.
A standard normális eloszlás eloszlásfüggvénye nem fejezhető ki elemi függvények segítségével, ezért táblázatos formában szokás megadni. Ennek a táblázatnak egy részlete:
A Φ függvény értéke közelítőleg számítógéppel is kiszámítható. Például az alábbi weboldalon
a megfelelő 'x' érték beírása után (m=0, σ=1 mellett) a "Calculate" gombra kattintva megkapjuk a Φ(x) függvény közelítő értékét ("Normal Probability").
Az 'm' és 'σ' paraméterű normális eloszlás eloszlásfüggvényét a standard normális eloszlás eloszlásfüggvényéből
F(x)=Φ((x−m)/σ)
módon kaphatjuk meg. (Például a táblázatból Φ(1.34)≈0.9099, ebből az m=1, σ=0.5 paraméterű normális eloszlás esetén az eloszlásfüggvény értékére 1.34*σ+m=1.67 miatt
F(1.67)≈0.9099
adódik.)
A normális eloszlás két fontos tulajdonsága:
(1) A binomiális eloszlás nagy 'n' és nem túl kis 'p' és 'q' (azaz "sem a 'p', sem a 'q' nem esik közel a 0-hoz", vö. Obádovics 1997: 91) esetén jól közelíthető az m=n*p várható értékű és σ2=n*p*q szórású normális eloszlással:
lim
n→∞
(
n
)
pk qn−k = Φ
(
x−n*p
)
k
√n*p*q
(2) Legyenek
ξi : Ω → ℝ (1≤i≤n)
azonos eloszlású,
m∈ℝ várható értékű és
σ∈ℝ, σ>0 szórású,
független valségi változók. Ezekre teljesül, hogy
lim
n→∞
P
(
ξ1+ξ2+...+ξn−n*m
<x
)
= Φ
(
x
)
σ*√n
vagyis elegendően sok, (a fentieknek megfelelően) azonos típusú és független valségi változó összege normális eloszlású (ún. centrális határeloszlás tétel).
Exponenciális eloszlás
A
ξ : Ω → ℝ
folytonos valószínűségi változót λ∈ℝ, λ>0 paraméterű exponenciális eloszlású valségi változónak nevezzük, ha sűrűségfüggvénye
f(x) =
{
λ*e−λ*x
ha x≥0
0
ha x<0
eloszlásfüggvénye pedig
F(x) = P(ξ<x) =
{
1−e−λ*x
ha x≥0
0
ha x<0
alakú.
Legyen
ξ : Ω → ℝ
exponenciális eloszlású valségi változó λ>0 paraméterrel. Ekkor
tehát c≠0 miatt M(ξ)/c ≥ P(ξ≥c) teljesül. (q.e.d.)
Például kockadobás esetén annak a valsége, hogy c=2-nél nagyobbat vagy azzal egyenlőt dobjunk, P(ξ≥2)=5/6≈0.83. Mivel M(ξ)=3.5, ezért M(ξ)/2=1.75, vagyis
P(ξ≥2)≤M(ξ)/2
nyilvánvalóan teljesül. Ha c=5, akkor P(ξ≥5)=2/6=1/3≈0.33, M(ξ)/5=0.7, vagyis
P(ξ≥5)≤M(ξ)/5
ebben az esetben is teljesül.
(2) Legyen ξ : Ω → ℝ tetszőleges valószínűségi változó, amelynek várható értéke M(ξ) és szórásnégyzete D2(ξ).
Ekkor tetszőleges λ>1 pozitív valós számra
P( ∣ξ−M(ξ)∣ ≥ λ*D(ξ) ) ≤ 1/λ2,
vagy ε=λ*D(ξ) jelöléssel
P( ∣ξ−M(ξ)∣ ≥ ε ) ≤ D2(ξ)/ε2
teljesül (ún. Csebisev-egyenlőtlenség).
(3) Legyen A∈Ω egy p=pA valószínűségű esemény,
és legyen
ηA : Ω → {0, 1, ..., n}⊆ℕ
egy 'n' darabos visszatevéses, független mintavétel mellett az A esemény gyakoriságát megadó valószínűségi változó.
Mivel tudjuk, hogy az ηA valségi változó
binomiális eloszlású, ezért
M(ηA)=n*p és
D2(ηA)=n*p*(1−p),
ezért a Csebisev-egyenlőtlenségből következik, hogy tetszőleges ε>0 pozitív valós számra
P
(∣
ηA
− p
∣
≥ ε
)
≤
p*(1−p)
n
n*ε2
teljesül (Bernoulli tétele, a nagy számok törvénye).
A tételből következik, hogy bármilyen kis ε>0 és δ>0 számokhoz találhatunk olyan (elegendően nagy) Nε∈ℕ számot, amelyre teljesül, hogy
– ha a mintavételek számát Nε-nál nagyobbra választjuk (azaz n≥Nε), akkor
– annak a valószínűsége, hogy az A esemény relatív gyakoriságának és valószínűségének abszolút eltérése az 'ε' értéket meghaladja,
– a 'δ' számnál kisebb lesz.
Ezt úgy is megfogalmazhatjuk, hogy n → ∞ esetén a relatív gyakoriság és a valószínűség eltérésének valószínűsége a 0-hoz konvergál.
A valószínűségek sorozatának ilyen értelmű konvergálását szokás sztochasztikus konvergenciának nevezni.
(4) Legyenek
ξ1 : Ω → ℝ,
ξ2 : Ω → ℝ,
...
ξn : Ω → ℝ,
azonos eloszlású, azonos 'm' várható értékű, és azonos σ>0 szórású független valószínűségi változók (azaz
M(ξk)=m és
D2(ξk)=σ2
teljesül, 1≤k≤n).
Ekkor tetszőleges ε>0 pozitív valós számra
P
(∣
ξ1+ξ2+...+ξn
− m
∣
≥ ε
)
≤
σ2
n
n*ε2
teljesül (a nagy számok gyenge törvénye).
Ebből következik, hogy 'n' darabos független mintavétel esetén az egyes mintavételek eredményét jelentő független, azonos eloszlású valségi változók számtani közepének és várható értékének az abszolút eltérése sztochasztikusan konvergál a 0-hoz.
Másképpen megfogalmazva a minta ún. empirikus középértéke (mintaközepe, empirikus várható értéke) sztochasztikusan konvergál a minta alapjául szolgáló valószínűségi változó várható értékéhez.
Bevezetve a
ξn=(ξ1+ξ2+...+ξn)/n
jelölést a minta empirikus középértékére, a nagy számok gyenge törvénye tetszőleges ε>0 pozitív valós szám esetén
P(|ξn−m|≥ε)→0
vagy
P(|ξn−m|<ε)→1
formában is kifejezhető (ahol a → jelöléssel a valószínűségek sorozatának sztochasztikus konvergenciáját fejeztük ki n→∞ mellett).
Statisztikai minták feldolgozása
A matematikai statisztikában egy jelenséget rendszerint egy (vagy több) valószínűségi változóval jellemzünk. A statisztikai mintavétel során az adott jelenségre vonatkozóan n darab (egymástól független) megfigyelést vagy kísérletet végzünk. A kísérletek során minden alkalommal meghatározzuk ("megmérjük") a minket érdeklő valószínűségi változó aktuális értékét. Ennek eredményeként egy n elemű számsorozatot, statisztikai mintát kapunk, amelyet a vizsgált valószínűségi változót reprezentáló 'n' darab azonos eloszlású és független valószínűségi változó megfigyelt értékének tekintünk.
A matematikai statisztika célja a vizsgált valószínűségi változó(k) jellemzőinek minél pontosabb (megbízhatóbb, hitelesebb stb.) meghatározása. A vizsgálatok során feltételezzük, hogy minél több kísérletet végzünk, eredményeink ("becsléseink") annál pontosabbak lesznek.
Legyen ξ : Ω → ℝ az általunk vizsgált valségi változó és
( ξ1=x1,
ξ2=x2, ...,
ξn=xn )
statisztikai mintavétellel kapott minta. A továbbiakban feltételezzük, hogy a ξi (1≤i≤n) valségi változók függetlenek, és eloszlásfüggvényük, valamint minden egyéb paraméterük (várható értékük, szórásuk stb.) megegyezik a vizsgált ξ valségi változó eloszlásfüggvényével és egyéb paramétereivel.
A ξ megfigyelt valségi változó empirikus eloszlásfüggvénye a következő:
Fn(x) =
1
Σ
ξi<x
1
n
Rendezzük el az (x1, x2, ..., xn) minta elemeit nagyság szerint, és jelölje
(X1, X2, ..., Xn)
a rendezett mintaelemeket, valamint
xmin=X1 és
xmax=Xn
a minta legkisebb és legnagyobb elemét.
Ekkor az empirikus eloszlásfüggvény a következőképpen is megadható (vö. Obádovics 1997: 104-105):
Fn(x) = 0, ha x≤xmin;
Fn(x) = k/n, ha
Xk<x≤Xk+1
(k=1,2,...,n−1);
Fn(x) = 1, ha xmax<x.
A fenti formula alapján Fn(x) értéke az x-nél kisebb megfigyelések számának relatív gyakorisága. Ezért egy [a,b)⊆ℝ intervallumra, elegendően nagy mintaszám (n>>1) esetén,
P(a≤ξ<b) ≈ Fn(b)−Fn(a)
teljesül.
A ξ megfigyelt valségi változó (relatív) gyakorisági hisztogramját a következő eljárással kaphatjuk meg:
(1) Határozzuk meg azt az [a,b)⊆ℝ intervallunot, amely a mintaelemek mindegyikét tartalmazza (azaz xi∈[a,b), 1≤i≤n). Például
a=inf{ xi | 1≤i≤n } és
b=sup{ xi | 1≤i≤n }
nyilvánvalóan megfelelő értékek.
(2) Osszuk fel az [a,b)⊆ℝ intervallumot 'r' darab részintervallumra
a=d0 < d1 < ... < dr=b
módon például úgy, hogy a kapott Di=[di−1,di) részintervallumok hossza megegyezik (azaz di−di−1=d, 1≤i≤r). Ebben az esetben r*d=b−a teljesül, azaz d=(b−a)/r.
(3) Legyen ki a Di részintervallumba eső mintaelemek száma (1≤i≤r). Ábrázoljuk a koordináta-rendszer x tengelyén az [a,b) intervallumot és ezen belül a Di részintervallumokat úgy, hogy minden Di részintervallumhoz egy 'd' széles és a ki értékkel arányos magasságú téglalapot rendelünk. Legyen a téglalap például
– y=ki vagy y=ki/n (Reimann-Tóth 1985: 131-132, Obádovics 1997: 106) vagy
– y=ki/d (Reimann-Tóth 1985: 130)
magasságú.
Mivel a gyakorisági hisztogram fenti módon történő készítése során 'd' a részintervallumok hosszát jelentette, az egyes Di részintervallumokhoz rendelt téglalapok területe a ki gyakoriságokkal, az ábrázolt téglalapok összegzett területe pedig a minta darabszámával (n=k1+k2+...+kn) arányos értéket fog megadni.
A ξ megfigyelt valségi változó sűrűségi hisztogramját a gyakorisági hisztogramhoz teljesen hasonlóan készíthetjük el, de az egyes Di részintervallumokhoz rendelt téglalapok magasságát
ki/(d*n)
módon állapítjuk meg. Ebben az esetben az ábrázolt téglalapok összegzett területe 1-et fog adni.
Jelöljük azt a függvényt, amelyet a sűrűségi hisztogramban megrajzolt téglalapok rajzolnak ki, fn(x) módon. Az így kapott empirikus sűrűségfüggvény segítségével megbecsülhetjük, hogy a ξ valségi változó értéke mekkora valséggel esik egy adott intervallumba.
Ha [a,b)⊆ℝ egy intervallum, elegendően nagy mintaszám (n>>1) és kis részintervallumok (d=di−di−1<<1, 1≤i≤r) esetén
P(a≤ξ<b) ≈
Σ
a≤di−1<di≤b
fn(di)*(di−di−1)
teljesül (a formulában az fn(di) tényezőben di helyett a Di intervallum bármelyik pontját választhatjuk).
Folytonos eloszlások esetében, folytonos f(x) sűrűségfüggvényt feltételezve a részintervallumok hosszát minden határon túl csökkentve (d→0) a fenti formula átmegy az f(x) (integrálható) sűrűségfüggvény [a,b) intervallumon vett határozott integráljába, amelynek kiszámításához az F(x) eloszlásfüggvényt mint primitív függvényt használhatjuk (F'(x)=f(x)).
Példaként hajtsuk végre a Weldon-féle kockadobási kísérletet m=10-szer megismételt dobássorozattal. Emlékeztetőül foglaljuk össze, hogy a korábban megadott mintapéldának megfeleltetve ez mit jelent:
– egy kísérlet egy kockadobás, amelyben N=6 "termékből" választunk;
– a kockával dobott minden érték (vagyis az egyes "termékek" kiválasztása) egyenlően valószínű (klasszikus valségi mező);
– a megfigyelt esemény (A) az 5-ös vagy 6-os dobás, azaz a termékek között s=2 darab "selejt" van (pA=2/6=1/3);
– egy kísérlet vagy dobássorozat (ξA) során n=12-szer dobunk, azaz 12 "terméket" választunk (visszatevéses mintavétellel) (Megjegyzés: itt 'n' nem a statisztikai mintavétel elemszámát jelenti, hanem egy kísérlet során a dobások számát; a statisztikai mintavétel elemszámát, azaz a kísérletek számát most 'm' jelöli);
– egy kísérlet során az A esemény ξA=k-szor következik be, azaz 'k' darab "selejtet" kapunk (0≤k≤12); ha egy adott kísérlet (mintavétel) során di≤k<di−1 teljesül, akkor a [di,di−1) intervallumhoz tartozó gyakoriság eggyel nő
(Megjegyzés: a hisztogramkészítéshez szükséges intervallumokba eső minták számát az alábbi táblázatban χ-vel fogjuk jelölni, ahol 0≤χ≤m teljesül);
– a kísérleteket eredetileg m=26306-szor hajtották végre, amely megfelelt a
( ξA1=k1,
ξA2=k2, ...,
ξA26306=k26306 )
statisztikai mintavételnek; az alábbi példában azonban egy m=10 elemű mintát használunk.
Az empirikus eloszlásfüggvény, Fn(x) ábrázolása
Figyeljük meg, hogy az empirikus eloszlásfüggvénynek az értékkészlet különböző pontjaiban szakadása van.
A görbe minden szakadáskor annyiszor emelkedik 1/n=0.1 értékkel, ahányszor az értékkészletben az adott érték előfordul.
A sűrűségi hisztogram ábrázolása
Figyeljük meg, hogy a különböző színű görbék alatti terület összege pontosan 1.
(az x tengely beosztása 1, az y tengely beosztása 0.1)
kék szín: d=2 hosszúságú intervallumok
sárga szín: d=1 hosszúságú intervallumok
A statisztikai mintavételben szereplő
( ξ1=x1,
ξ2=x2, ...,
ξn=xn )
valségi változók egy alkalmasan választott
g(ξ1,ξ2,...,ξn)
függvényét statisztikai függvénynek vagy statisztikának nevezzük.
Ilyen statisztikák például az (empirikus) mintaközép vagy az empirikus szórásnégyzet.
(1) A ξ valószínűségi változó megfigyelésével kapott
( ξ1=x1,
ξ2=x2, ...,
ξn=xn )
statisztikai minta számtani közepét, azaz a
ξ = (ξ1+ξ2+ ... +ξn)/n
statisztikát mintaközépnek (empirikus középértéknek vagy empirikus várható értéknek) nevezzük. Ha a ξ megfigyelt valségi változó várható értéke
M(ξ)=m és szórásnégyzete D2(ξ)=σ2, akkor a mintaközép várható értékére és
szórásnégyzetére
M(ξ)=M(ξ)=m, és
D2(ξ)=D2(ξ)/n=σ2/n
teljesül. (Érdemes megjegyezni, hogy a mintaközép szórása 'n' növekedésével jelentősen csökken.)
(2) A ξ valószínűségi változó megfigyelésével kapott
( ξ1=x1,
ξ2=x2, ...,
ξn=xn )
statisztikai minta esetében az
statisztikát korrigált empirikus szórásnégyzetnek nevezzük.
Ha a ξ megfigyelt valségi változó szórásnégyzete D2(ξ)=σ2, akkor az empirikus és korrigált empirikus szórásnégyzet várható értékére
M(S2(ξ))=σ2*(n−1)/n és
M(Sk2(ξ))=σ2
teljesül. (Ha a mintaszám nagy, azaz n>>1, akkor az empirikus szórásnégyzet várható értéke közelítőleg a ξ valségi változó szórásnégyzetét adja.)
(3) A ξ és η valségi változók empirikus korrelációs együtthatója az
rξη
= (ξ1*η1+
ξ2*η2+
...+
ξn*ηn)/n
jelöléssel
r = (rξη −
ξ*η) /
(S(ξ)*S(η))
módon számítható ki (Reiman-Tóth 1985: 231).
Példaként határozzuk meg a ξ és η valségi változók együttes eloszlásának ismeretében az empirikus mintaközepet, szórást és korrelációs együtthatót.
index
ξ
η
A ξ és η valségi változók empirikus mintaközepe:
ξ=
η=
A ξ és η valségi változók empirikus és korrigált empirikus szórásnégyzete:
S2(ξ)=
⇒ S(ξ)=
Sk2(ξ)=
⇒ Sk(ξ)=
S2(η)=
⇒ S(η)=
Sk2(η)=
⇒ Sk(η)=
A ξ és η valségi változók empirikus korrelációs együtthatója:
r(ξ,η)=
Ha a mintaelemek generálásakor a Mintavétel (1,2,3) gombra kattintottunk, akkor ellenőrzésként adjuk meg a
ξ : Ω→{1,2,3}
és
η : Ω→{1,2,3}
valségi változók együttes eloszlását az egyes értékek együttes előfordulásainak relatív gyakorisága alapján a korábbi példában szereplő táblázathoz hasonlóan. Ezután számoljuk ki a valségi változók peremeloszlását és a valségi változók főbb jellemzőit. Ha így járunk el, a fenti értékekkel megegyező értékeket kell kapnunk.
ξ ↓ / η →
y1=1
y2=2
y3=3
Σ(sorok)
x1=1
wξη(x1,y1)
wξη(x1,y2)
wξη(x1,y3)
wξ(x1)
x2=2
wξη(x2,y1)
wξη(x2,y2)
wξη(x2,y3)
wξ(x2)
x3=3
wξη(x3,y1)
wξη(x3,y2)
wξη(x3,y3)
wξ(x3)
Σ(oszlopok)
wη(y1)
wη(y2)
wη(y3)
A ξ és η valségi változók várható értéke:
M(ξ)=
M(η)=
A ξ és η valségi változók szórásnégyzete:
D2(ξ)=
⇒ D(ξ)=
D2(η)=
⇒ D(η)=
A ξ és η valségi változók kovarianciája:
Cov(ξ,η)=
A ξ és η valségi változók korrelációs együtthatója:
R(ξ,η)=
Irodalom- és forrásjegyzék
Bíró Fatime; Vincze Szilvia 2010. A gazdasági matematika alapjai. Debrecen: Debreceni Egyetemi K.
Bognár Jánosné et al. 1971. Valószínűségszámítás feladatgyűjtemény. Budapest: Tankönyvk.
Csatlósné Fülöp Sára 1996. Kombinatorika, valószínűségszámítás. In: Pappné Ádám Györgyi (szerk.) 1996. 155-174.
Cser Andor; L. Ziermann Margit; Reményi Gusztáv 1962. Matematikai zsebkönyv. Budapest: Tankönyvk.
Feller, William 1978. Bevezetés a valószínűségszámításba és alkalmazásaiba. Budapest: Műszaki K.
Obádovics J. Gyula 1997. Valószínűségszámítás és matematikai statisztika. Budapest: Scolar K.
Obádovics J. Gyula; Szarka Zoltán 2009. Felsőbb matematika. Budapest: Scolar K.
Pappné Ádám Györgyi (szerk.) 1996. Matematika az általános képzéshez a tanítóképző főiskolák számára. Budapest: Nemzeti Tankönyvk.
Reimann József; Tóth Julianna 1985. Valószínűségszámítás és matematikai statisztika. Budapest: Tankönyvk.
Solt György 1971. Valószínűségszámítás. Példatár. Budapest: Műszaki K.
Szabó István 1996. Kombinatorika, valószínűségszámítás. In: Balassa Zsófia (szerk.) 1996. Matematika feladatgyűjtemény az általános képzéshez a tanítóképző főiskolák számára. Budapest: Nemzeti Tankönyvk. 82-91.
Vilenkin, N. J. 1987. Kombinatorika. Budapest: Műszaki K.
Vincze Szilvia, Bíró Fatime 2000. Bevezetés az alkalmazott matematikába. Debrecen: Debreceni Egyetem Debreceni Egyetem Agrártudományi Centrum.
Závoti József 2010. Matematika III. 4. A valószínűségi változó és jellemzői. Sopron: Nyugat-magyarországi Egyetem, Geoinformatikai Kar.

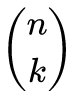 *k3
(ismétléses permutáció,
*k3
(ismétléses permutáció, 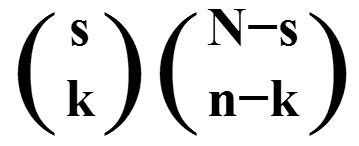 *n!
adódik.
*n!
adódik. féleképpen lehet kihúzni. Ha egy "feladott" szelvényen öt számot adtunk meg, a kérdés az, hogy elvileg hány olyan lottószelvény létezik, amelyen a megadott számokból legalább kettő szerepel (ti. ezek lesznek a számunkra "kedvező" esetek).
Egyrészt az öt számból a két kihúzott számot
féleképpen lehet kihúzni. Ha egy "feladott" szelvényen öt számot adtunk meg, a kérdés az, hogy elvileg hány olyan lottószelvény létezik, amelyen a megadott számokból legalább kettő szerepel (ti. ezek lesznek a számunkra "kedvező" esetek).
Egyrészt az öt számból a két kihúzott számot
 féleképpen tudjuk kiválasztani; másrészt pedig ezekhez a fennmaradó 88 számból
féleképpen tudjuk kiválasztani; másrészt pedig ezekhez a fennmaradó 88 számból
 féleképpen választhatunk tetszőleges további három számot (megengedve azt is, ha pl. mind az öt számot eltaláljuk; ha csak a kettes találatokat vizsgáljuk, 88 helyett 85-öt kell írnunk). Az általunk megadott öt számból legalább két számot tartalmazó lottószelvények száma tehát
féleképpen választhatunk tetszőleges további három számot (megengedve azt is, ha pl. mind az öt számot eltaláljuk; ha csak a kettes találatokat vizsgáljuk, 88 helyett 85-öt kell írnunk). Az általunk megadott öt számból legalább két számot tartalmazó lottószelvények száma tehát
")
 alapján")
")